���̃y�[�W�̃X���b�h�ꗗ�i�S28�X���b�h�j![]()
| ���e�E�^�C�g�� | �i�C�X�N�`�R�~�� | �ԐM�� | �ŏI���e���� |
|---|---|---|---|
| 1 | 9 | 2025�N1��27�� 21:17 | |
| 0 | 5 | 2025�N1��23�� 12:47 | |
| 17 | 38 | 2021�N10��11�� 00:45 | |
| 44 | 80 | 2019�N11��5�� 22:52 | |
| 18 | 26 | 2019�N10��7�� 20:44 | |
| 0 | 10 | 2019�N5��11�� 10:12 |
- �u����̍i���݁v�̖��ԐM�A�������͍ŐV1�N�A�����ς݂͑S���Ԃ̃N�`�R�~��\�����Ă��܂�
NAS(�l�b�g���[�NHDD) > ASUSTOR > NIMBUSTOR 2 AS5202T
EZsync���C���X�g�[�����Ă����̓����g�c�c�ɓ���Ă����X�O�OGB�قǂ̃f�[�^��ɓ���A�摜�A�o�c�e�̃t�H���_��I�����ē��������n�߂��̂��A�P�O���O�ł�
�P�O���Ԃ�����nas���ғ��������ςȂ��Ȃ̂ł����A���̏����������������t�H���_�͂Q�łR�PGB�قǂ�����������Ă��܂���
�]��ɂ����Ԃ������肷���Ă���Ɗ�����̂ł������ꂪ�W���Ȃ̂ł��傤���H
��̂ł����d���s���O�ɓ������I�����ĊJ���āA�P�V���Ԍギ�炢���ċA��Ċm�F���Ă݂��
���������i�����j�����̐�����1���O��ł�
nas�ɓ����Ă�HDD�͂Q�ŗ����Ƃ�WD��RED���̂UTB��
�����ɓ����Ă铯�����̂g�c�c���v�c��BLUE�̂PTB�ł�
NAS��RAID1�Ŏg�p���Ă܂�
����A�}�]���ōw������USB�P�[�u����PC�ƌq���œ��������Ă܂�
https://amzn.asia/d/hsjuBjD
�ꉞ�]�����x�̃`�F�b�N�������Ă݂��̂ʼn摜���\��܂�
![]() 0�_
0�_
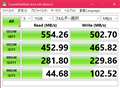 |
|---|
�摜���\��ĂȂ������̂ŘA�����߂�Ȃ���
�����ԍ��F25217397
![]() 0�_
0�_
>����A�}�]���ōw������USB�P�[�u����PC�ƌq���œ��������Ă܂�
����ŁANAS��PC�����Ă���Ă��ƁH
����ȂȂ������Ă��A�g���Ȃ���[�B
PC���A����LAN�łȂ��łȂ��H
�L��LAN�łȂ��Ȃ��ƁA���\�o�Ȃ���[�B
>�ꉞ�]�����x�̃`�F�b�N�������Ă݂��̂ʼn摜���\��܂�
����́ANAS��PC�̂������̑��x������H
����ɂ��ẮA�u���x�o����(;^_^A�v�̂�[�ȋC���B
2.5GLAN�łȂ��ł���́H�D�D�D�Ⴄ�悤�ȁD�D�D�B
�����ԍ��F25217869
![]() 0�_
0�_
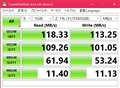 |
|---|
�������炢�̂���������
USB��PC�Ɛڑ�������I�t���C����Raid�Ή�HDD�P�[�X���l�Ɏg���镨���Ɗ��Ⴂ���Ă܂����B�B�B
��ɓ\�����摜�̌v���̎����Ԃ�l���h���C�u�I�����Ȃ��܂܌v�������Ǝv���܂��B�B�B
���Ԃ����SSD�̌v�����ʂł�
���\����̂�NAS�̌v�����ʂł�
LAN�͍��̏�������nas���P�M�K��LAN�|�[�g�L���Ŏg�p���Ă܂�
�������̃y�[�X�ōs���Ɠ��������܂ł�1�����ȏ�̎��Ԃ������肻���ŕs���Ƃ����̂������Ă��ꂪ�W�����x�Ȃ̂��ǂ����ӌ����~�����ł�
�����ԍ��F25218506
![]() 0�_
0�_
��NAS�̐ݒ��M���Ă�4�̂��鎖�ɋC�Â��܂���
�P��AES�̓������Ɉꎞ��~�����āA�ĊJ���悤�Ƃ���ƕK�������Ȃ��ɂȂ��Ă��܂���
2�̓t�H���_�̖��O�������ă��l�[�����Ȃ��ƃG���[�œ������i�s�s�\�ɂȂ鎖
�i�s�s�\�ɂȂ�x�Y���t�H���_�����l�[�����āAAES�ꎞ��~���������ĊJ������Ɖ����Ȃ��̃G���[�ɂȂ�̂ŋ����I���������ēxAES���N������Ɠ������ĊJ����Ƃ�������
�ݒ�łǂ��ɂ��Ȃ邩�ƃ}�j���A����Ђ��[����ǂ�A�l�b�g�Ō������Ă݂܂������肪����͂���܂���ł���
�R�ڂ�AES���N�����Ă����̂P�O�`�Q�O�b�Ԃ̓t�@�C���̓������X���[�Y�ɐi�s���鎖
����ȍ~��1���ԑ҂��Ă��t�@�C�����X�L�����͂���邪�A����������Ȃ���
�ŏ��̂P�O�`�Q�O�b�Ԃő�̉摜�t�@�C�����S�`�V���قǓ�������Ă���x�ł�
4�߂�AES���g�p�����A�t�@�C����t�H���_�����̂܂�NAS���ɕ��荞�ނƂȂ�̖��������A�b�v���[�h�����Ƃ�����
���X�u�ւ��[�����Ńt�@�C�����������A�b�v���[�h���Ȃ��ł��A�����œ������Ă����I�g��Ȃ���͂Ȃ����I�v�Ƃ����l����EZsync���g�p���Ă���̂ł��ꂪ�g���Ȃ��Ƃ����̂͂Ȃc�O�Ȋ����E�E�E
�s��Ȃ̂��ݒ肪�����̂�asustor�̃T�|�[�g�ɓd�b�������Ă݂܂������A���{��ł͂Ȃ��K�C�_���X�����ꂽ�̂Ŗ����ł���
���{�㗝�X�̃T�|�[�g�_�C���������������̂łP�O������d�b��t�J�n���邻���Ȃ̂œd�b���Ă݂܂�
�����ԍ��F25218643
![]() 0�_
0�_
�ꔭ�ڂ̃R�s�[�́A�h���C�u���蓖�Ă��āA�ӂ[�̃G�N�X�v���[���[�Ŏ蓮�S�R�s�[���āA���������EZsync���Ă��Ă݂���[�B
�����ԍ��F25218840
![]()
![]() 0�_
0�_
�������炢�̂���������
�����悤�Ȃ��Ƃ��T�|�[�g�ɂ������܂���
�l�̑S�̗̂e�ʂ��傫������̂ŏd���Ȃ��Ă�\��������ƌ���ꂽ�̂ō��蓮�őS�R�s�[����ׂ�
�Ƃ肠�����K���ɂQ�P�SGB�̃t�H���_����荞�̂ł����P�O�b�ɂP�̃t�@�C����1�����x�����i�s���Ȃ��̂ł���܂����X���Ԃ�������܂��ˁE�E�E
NAS�̓������g�p���R�O�`�R�T���ACPU�g�p�����P�T���ȉ�
������i74790�ɂP�UGB�̃������e�ʂ������ă^�X�N�}�l�[�W���[�Ō������
CPU�S�O�`�T�O���ȉ��A�������R�T�`�R�W���i���icom�J���Ȃ���j�ł���
�g�p���̊���NAS�̃A�v�������̂��������삪�d���Ȃ��Ă܂��E�E�E
�P�O���ԂقǑO�ɃR�s�[���čs���ċA���Ă����炐�����ċN���Ă��̂œr���Ńt���[�Y�����̂��ƋC�Â��܂������R�U�P�O�t�@�C���̓��P�X�O�O���x��������ĂȂ������ł�
����͍���E�E�E
NAS�̃������e�ʑ��₵���炱������������y���Ȃ�܂����H
�����ԍ��F25219670
![]() 1�_
1�_
�܂��͒ʏ�̃t�@�C���R�s�[�����܂��������ǂ����̌������Ă݂Ă͂������ł��傤���B
(USB��PC�Ɛڑ�����悤�ɂ͂Ȃ��Ă��Ȃ��Ǝv���܂��̂ŁA�O�����ق����悢�Ǝv���܂�)
AS5202T�̃x���`�}�[�N���������M�K�r�b�gLAN�ڑ��ł́A�قڍő呬�x���łĂ���悤�Ɏv���܂��B
���Ƃ̓R�s�[����PC��i7 4790�Ƃ̂��Ƃł��̂ŁAOS�͂Ȃɂ����g���ł��傤���B
�f�[�^�������Ă���Ƃ����HDD�Ƃ̂��Ƃł��̂ŁA������̃h���C�u�̃x���`�}�[�N�����Ă݂Ă��������B
���Ԃ�AAS5202T�ւ̏������ݑ��x��������HDD�̓ǂݍ��ݑ��x���x����������܂���B
�ǂ��炩�x�����̑��x���t�@�C���R�s�[�̓]�����x�ɂȂ�܂��B
�]�����x��100MB/s�������Ɖ��肷���200GB�̃f�[�^�ł���(200GB×1000)/100MB/s��2000�b�A
2000/60�Ŗ�33���قǂŃR�s�[���I���Ǝv���܂��B
�]�����x��50MB/s�����łĂ��Ȃ��ꍇ�́A���̔{�Ŗ�1���Ԃقǂ����邩�ƁB
���Ƃ�Windows�ł̓t�@�C�����Ƃ��Ďg���镶���ł����AAS5202T��LINUX�x�[�X��NAS�ł��̂ŁA
LINUX�Ŏg���Ȃ��������܂܂�Ă��Ȃ����̊m�F�Ƃ��B
�t�H���_�̊K�w���[�����Ȃ��Ƃ��t�H���_�����������Ȃ����Ƃ��B
�Ō�Ƀt�@�C���T�[�o�[�Ƃ��ė��p�݂̂ł�����A�W���̃������e�ʂœ��ɖ��͂Ȃ��Ǝv���܂��B
�����ԍ��F25219790
![]()
![]() 0�_
0�_
�摜�Ǘ��Ƃ��̃A�v���W�A�����f�t�H���g�̂܂�܂ŁA���̂܂܃C���X�g�[�������肵�ĂȂ�������H
�A�v���������܁A�Ă����Ԃ�������A��������A���[��ԁA�A���C���X�g�[�����Ă݂Ă���A�S�R�s�[���Ă݂���ǁ[������H
>�P�O���ԂقǑO�ɃR�s�[���čs���ċA���Ă����炐�����ċN���Ă��̂œr���Ńt���[�Y�����̂��ƋC�Â��܂���
����́ANAS�W�Ȃ����āAPC�ɖ�肪�����łȂ�������H
PC�̃n�[�h�f�B�X�N�ɃG���[������Ƃ��B
����A���J�������ǂˁB
NAS���������ɂȂ������āAPC���ċN��������͂��Ȃ���[�B
�����ԍ��F25219902
![]()
![]() 0�_
0�_
���������l�̏ł����B
EZ sync���t�@�C���X�L�����Ŏ~�܂��Ă��܂�����A���t�@�C�����������A�b�v���[�h����܂���ł����B
HDD�̔M�\�����ȂƎv���ăt�@���ŗ�p���Ă����ʂȂ��B
�G�N�X�v���[���[�Ŏ蓮�A�b�v���[�h�����Ƃ��됳��ɋL�^���ꂽ�̂�EZ sync���_���ȂȂƔ����B
EZ sync�̓A���C���X�g�[�����A�t���[�\�t�g�́uRealSync.exe�v���g�����Ƃɂ��܂����B
RealSync��HDD����HDD�ւ̃R�s�[�A�����������ł���t���[�\�t�g�ł��B
�l�b�g���[�N�h���C�u�ɂ��Ή����Ă���̂�HDD����NAS�փR�s�[����悤�ɐݒ肵�܂����B
�����ԍ��F26052625
![]() 0�_
0�_
NAS(�l�b�g���[�NHDD) > ASUSTOR > AS3102T
���Âōw�����A�A���h���C�h�ŃA�N�Z�X���Ďg�p���Ă��܂����B�g�т������AiPhone14�ɂ����Ƃ���A�N�Z�X�ł��Ȃ��Ȃ�܂����B
iPhone�ł́Aaidata�A�v���AiPhone�̃v���C���X�g�[���̃t�@�C���A�v�����ɃA�N�Z�X�ł��܂���B
�����[�g�T�[�r�X�����p�ł��Ȃ��Ƃ̃A���[�g���ł܂��B
���̃A���h���C�h�ł͓���ID�APW�Ŗ��Ȃ��A�N�Z�X�ł��܂��B
�����ANAS�ݒ肪�K�v�Ȃ̂ł��傤���H
�K�v�ȃT�[�r�X�̋N����ANAS�ւ̃A�v���̃C���X�g�[�����K�v���ANAS�̍ċN�����_���ł����B
�ڂ������A�����������肢�v���܂��B
�����ԍ��F26033715�@�X�}�[�g�t�H���T�C�g����̏�������
![]() 0�_
0�_
���́@NAS�@�Ł@SMB�@���N���ł��Ă܂����ˁH�@�܂��́A�ł��܂����ˁH
NAS�Ɂ@SMB�@�̐ݒ�����ā@iPhone �t�@�C��APP�@����A�N�Z�X�ł��܂����ˁH
�ꉞ�A���S�̂��߁ASMB�R�D���@�̑I��������������A�����I������ˁB
�ŁA�ǂ��H
�����ԍ��F26034503
![]()
![]() 0�_
0�_
�����肪�Ƃ��������܂��B
SMB�͋N�����Ă��܂��B
iPhone��app������A�N�Z�X�ł��������Ă܂��B
��xNAS������������K�v������̂ł��傤���H
iPhone����A�N�Z�X�o���Ȃ����Ăˁc
�g�����ɂȂ�܂���B
�F�X�Ƃ���ׂ��̂ł����A�H�Ȃ��Ƃ݂����Ńl�b�g�ł��q�b�g���܂���B
����܂����B
�����ԍ��F26034549�@�X�}�[�g�t�H���T�C�g����̏�������
![]() 0�_
0�_
�킽�����́AiPhone �Ɓ@WinPC�@�Ƃ̂������ŁA�t�@�C���V�F�A�@���Ă邋��ǂ��A�S�R���Ȃ���ˁB
iPhone ����@�e�������`�o�o�Ł@SMB�F//�h�o�A�h���X�@�łȂ���́H
�����ԍ��F26034580
![]()
![]() 0�_
0�_
�����ł����B
��͂�A��薳���g���Ă܂���ˁB
�g���Ȃ��������������ł��傤���B
�A�N�Z�X�́ASMB�F//�h�o�A�h���X�ł���Ă܂����A�q����܂���ˁB
��x�ANAS����������������ǂ���������܂���ˁB����ł����߂Ȃ甃���ւ������Ȃ����ȁH�Ǝv���Ă܂��B
���肪�Ƃ��������܂����B
�����ԍ��F26034766�@�X�}�[�g�t�H���T�C�g����̏�������
![]() 0�_
0�_
�������A�Đݒ�Ŗ�薳���A�N�Z�X�ł���悤�ɂȂ�܂����B���������������̂��s���ł����B
�����ւ����������Ă����̂ŁA����ɂȂ�A������܂����B�g��������ǂ��̂ŁA�܂��܂��g�������Ǝv���܂��B
�����ԍ��F26047398
![]() 0�_
0�_
NAS(�l�b�g���[�NHDD) > ASUSTOR
�S�ʂł͂Ȃ��A�ʋ@��ŗL�̌f���ɓ��e���Ă������̂ŁA���炽�߂đS�ʂł��邱����Ɂi�āj���e�����Ē����܂��B�i�@��ŗL�Ƃ������ADM�̘b�Ȃ̂Łj
������P
������HDD2�䂪MediaError�ƂȂ������̂́AASUSTOR��RAID1�͂Ȃ��Ȃ��D�G�炵���A��Q��������{�����[���ɂ͕��ʂɃA�N�Z�X�o���Ă��܂����i�ߋ��`�B���R�͎���2�ɋL���܂��j�B�����ł������������������̂ł����A�ǂ����HDD���Ɍ�������Ηǂ��ł��傤���H�T�|�[�g�Ɏ��⒆�Ȃ̂ł����A6���Ԍo�������݂��L���ȉ�����܂���̂ŁA�����q���g�ƂȂ�A�h�o�C�X�ł�������K���ł��B
�\���F
vol1 Disk1, Disk3 ��RAID1
vol2 Disk2, Disk4 ��RAID1
��L��Disk2�y��Disk4����������MediaError�i�K���ɂ��Z�N�^�ԍ��͈قȂ�j�B
ASUSOTR�̃T�C�g���Q�Ƃ���ƁARAID1�̕Б�����Q���N�������ꍇ�͓��Y�f�B�X�N�����������ĐV�����f�B�X�N�����邾���ʼn�������|�̕���������܂����A���h���C�u�ɐ�LED���_������ł͂ǂ��炩���������f�[�^������ꂸ�ɍςނ̂������������B
������2
�ǂ�����v�����Ȃ������̂ŁA�܂��̓o�b�N�A�b�v����낤�ƁA�璷���̂Ȃ��Ȃ���volume2�̃f�[�^��volume1�ցiASUSTOR�̃t�@�C���}�l�[�W���ɂāj�R�s�[���Ă����Ƃ���AASUSTOR���n���O�A�b�v���Ă��܂��܂����B
����Disk2��LED�̂ݖҗ�ɓ_�ł��Ă���̂ŁA�{�^���������ɂ�鋭���d���f�͕|���Ď����Ă��܂���B
�i�n���O�A�b�v����O�́ADisk4��S�Ă�LED�����ł��Ă��܂����j
�n���O�A�b�v�̏Ǐ�Ƃ��ẮA
�@�E�{�̉t���̕\���͒ʏ�E���獶�փX�N���[������̂ł����A���ꂪ�r���Ŏ~�܂����܂܁B
�@�ELAN����ڑ��ł��Ȃ��i���O�I����ʂɂ�����Ȃ��j
�@�Eping�ɂ�����������
�ł��B
���̏�Ԃ���������ɂ́A�d�������������Ȃ��ł��傤���B
�i�ق��̋Z���������ł����炲�������������܂��ƍK���ł��j
�ȏ��낵�����肢���܂��B
![]() 0�_
0�_
��KA-7300����
ASUSTOR��NAS�͎g�������Ƃ�����܂���̂ŁA���m�ȏ�K�v�ȏꍇ�̓X���[���Ă��������B
�����̏�Ԃ���������ɂ́A�d�������������Ȃ��ł��傤���B
HDD�ُ̈�ɂ��SATA�̃��Z�b�g���J��Ԃ��Ă��āA�V�X�e�������̎��Ƀ��\�[�X�������Ȃ���Ԃ��Ǝv���܂��B
���̏�ɂ��Ȃ��̂ʼn��Ƃ������Ȃ��̂ł����A�����Ȃ琔�\���܂��Ă��������Ȃ��ꍇ�́A������߂ăV���b�g�_�E�������܂��B
�����{�^������������t���Ȃ���������܂���c
�ŋ߂�NAS��OS�̓x�[�X��Linux���g���Ă��܂��B
ADM�����l�ɂȂ邩�Ǝv���܂��ARAID���\�t�g�E�F�ARAID��mdadm�Ƃ����\�t�g�E�F�A��ō\�z����Ă��܂��B
��vol2 Disk2, Disk4 ��RAID1
����L��Disk2�y��Disk4����������MediaError�i�K���ɂ��Z�N�^�ԍ��͈قȂ�j�B
RAID1�̓~���[�����O�ł��̂ŁARAID5��RAID6�̂悤�ȃp���e�B�ɂ��C���͏o���܂���B
����̂悤�ɃA���C��g��ł���HDD�S�ĂɃ_���[�W�������Ԃł��ƁA�S�Ẵf�[�^�𐳏�ȏ�Ԃւ̕����͓���ł��B
�܂��ARAID�̏�Ԃ��s��(�����炭�N���b�V�����Ă�)�ł��̂ŁAADM�ォ��͂P�����蒼���ɂȂ邩�Ǝv���܂��B
��Ƀ��f�B�A�G���[�ƂȂ���HDD�́ARAID�A���C����藣����Ă�Ǝv���܂���
���̎��f�B�X�N�}�l�[�W���[�Ń{�����[���̃X�e�[�^�X�̓f�O���[�h(��)�ɂȂ��Ă��܂��������H
�����f�O���[�h(��)��ԂŁA���̃{�����[���̃f�[�^���X�V���Ă����ꍇ�́A�c�����P��ɂ����ۑ�����Ă��܂���B
�c�����P�䂪���f�B�A�G���[�ƂȂ������A�{�����[���̃X�e�[�^�X���N���b�V���Ȃǂ̌��t���g���Ă����ꍇ��
�Q��Ƃ�mdadm�̃X�e�[�^�X��faulty���Z�b�g����Ă��܂��Ă邩�Ǝv���܂��B
���̂悤�ȏꍇ�̈�ʓI�ȕ��@�ł̏C����i�����͒m��܂���B
������xLinux�̑���Ɋ���Ă���Ȃ�A�Q���HDD���疳���ȃt�@�C���݂̂��W�߂鎖�͏o���邩������܂���B
�����A�s�ǃZ�N�^�̂���HDD��RAID�A���C���쐬���鎖�͂����߂��܂��AADM�ł���点�Ă���Ȃ��ł��傤�B
�X�y�A��HDD�͏��������������Ȃ̂ł��傤���H
�Ƃ肠�����ł��T�|�[�g����̉���������Ƃ����ł��ˁB
���ƁASSH�Ƃ��������[�g�R���\�[�����g����Ȃ�
cat /proc/mdstat
�ł�����xRAID�̏�Ԃ����邩�Ǝv���܂��B�Q�l�܂łɁB
�����ԍ��F24358487
![]() 1�_
1�_
������0220����
ASUSTOR��NAS���g�������Ƃ͖����Ƃ���Ȃ�����A������̌f���ł������ɕx�ރA�h�o�C�X�����肪�Ƃ��������܂��B
�o���������f�[�^���~�o�������̂ŁA���Y�{�����[���̃f�B�X�N�A�N�Z�X���p�����Ă���ł̃V���b�g�_�E����i�ɔY��ł���A5���قǎ肪�o���Ă��Ȃ���Ԃł��B
# �����������t���Ȃ��A�m���ɂ��������P�[�X���L�蓾�܂��ˁB
�i�T�|�[�g�������Ɖ��Ă������̕��@�����{����̂ł����j
RAID1�̘b�ɂȂ�܂����A����̌��ł�ASUSTOR�̍��̗ǂ��Ɋ��ӂ��Ă��܂��i�T�|�[�g�̉����̈����͍����ł����j�B
�悭����i���`���b�eRAID1�iMASTER�ɏ�Q���o���ꍇ�͊��S��SLAVE�ɐ�ւ���Ă��܂��^�C�v�j���ƁA����̃P�[�X�i����MediaError�j�͑S�łɂȂ�Ǝv���܂��BASUSTOR�̏ꍇ�AHDD���̂��̂�MediaError�ƂȂ��Ă�����̂́A�ǂ����HDD��RAID1�{�����[���ɑg�ݍ��܂ꂽ�܂܂̏�Ԃł���ARAID�{�����[���ւ͖��Ȃ��A�N�Z�X�ł��Ă��܂����B�{�����[���̃X�e�[�^�X�́A�ʏ�͏�Q���N�������h���C�u�ւ̑ϋv����1��ƕ\������Ă��܂����A������0�ɕς���Ă����Ǝv���܂��i�Q�ĂĂ����̂ł���o���j�B
����䂦�AMediaError���N������HDD�ō\�������{�����[��2�ւ̃A�N�Z�X���̓G���[�ӏ��܂�Disk2���g���A�G���[�ӏ��̂�Disk4���g���Ă����̂��낤�Ɓi��������Ɂj�v���Ă��܂����B�Ƃ͂����S�f�[�^�o�b�N�A�b�v���s�����Ƃ���r���Ńn���O�A�b�v�����̂ŁA�����������炻�̕����̋������ア�̂�������܂���B�i�Ȃ̂ŃT�|�[�g�̉�S�҂��ɂ��Ă��܂��j
HDD�����ł̃Z�N�^��֏������s�ƂȂ����̂ł��傤����ANAS(ASUSTOR)���̂̕���BBM(BadBlockManagement)�A������PDM(PredictiveDataManagement)�ƌĂ��悤�ȋ@�\��������Ă���Ă���i�ʃA���C�Ƀf�[�^���z���o���Ȃ��Ƃ��jRAID1�A���C�̕Б�����������`�Ŏ����Ȃ����Ɗ��҂��Ă��܂��B����ASUSOTR�T�C�g�̃J���b�W�i�Z�p���́j�Ȃǂ����Ă������������L�ڂ͂Ȃ��̂Ŗ����Ȃ̂�������܂���B
������������mdadm�̘b���炷��ƁA���̕ӂ͊��Ҕ��Ƃ������Ƃł��ˁB
������ɂ���A�����p��HDD2��y�ыz���o���Ɏg����̈�i��RAID1�̃{�����[��1�j���������܂����B
�Ȃ�TeraTerm��SSH���|���Ă݂܂������A�������Ȃ��ʖڂł����B
�i���������g�������ł���Ƃ͒m��Ȃ������̂ŁA���㊈�p�����Ă��������܂��j
�����ԍ��F24358931
![]() 0�_
0�_
��KA-7300����
�@��ɂ�邩�Ǝv���܂����A�t�����g�p�l���ɉt���f�B�X�v���C������@��Ȃ�
�Ђ���Ƃ���ƁA���̉��ɂ������{�^�������Ă܂��H
�^�Ԃ�����Ȃ��̂ŁA���̋@�\�����邩�܂Ŋm�F�o���܂��{�^������ŃV���b�g�_�E����NAS�Ɏw���ł��Ȃ����ȂƎv���܂��B
mdadm�̏ꍇ�AHDD�̏�Ԃ���قǍ����Ȃ����ReadOnly�ɂȂ�܂����A���[�U�[������o����悤�ɂ��Ă���܂��B
���{�����[���̃X�e�[�^�X�́A�ʏ�͏�Q���N�������h���C�u�ւ̑ϋv����1��ƕ\������Ă��܂����A������0�ɕς���Ă����Ǝv���܂��i�Q�ĂĂ����̂ł���o���j�B
���̃{�����[����RAID�A���C��Degraded�̏�Ԃł��鎖�͊m���݂����ł��ˁB
�ł��̂ŏ��߂Ɍ̏Ⴕ��HDD�͂��̎��_�ȍ~�͍X�V����ĂȂ��Ƃ݂Ȃ������������ł��B
�����V���b�g�_�E���o�����ꍇ�́A�ł����猻��ێ���D�悵��NAS�{�̂���Q��Ƃ��O���Ă�������������ł��B
ADM�����l���Ǝv���܂����A�eHDD�͂������̃p�[�e�B�V�����ɕ������OS(ADM)�̊�{�̈�ƃf�[�^�̈�A���̑��Ƃ����������ɂȂ�܂��B
�f�[�^�̈�̃p�[�e�B�V�����𑩂˂������{�����[��(RAID)�Ƃ��Ďg���܂��B
�eHDD��RAID�A���C�Ɏg����p�[�e�B�V�����ɂ�Super block�ƌĂ��RAID�̊Ǘ��f�[�^������܂��ARAID1���~���[�����O�ƌ����܂���Super block�����̓��j�[�N�œ����ɂ͂Ȃ�܂���B
HDD�̃p�[�e�B�V����(GPT)��Super block�������̏ꍇ�́ALinux PC�Ɛڑ����鎖�ŏ̊m�F�ƃT���x�[�W���\�ȏꍇ������܂��B
�����A����̃P�[�X�ł͕s�ǃZ�N�^�ɂ��t�@�C���ɉe��������\��������܂��̂ŁAHDD�̗e�ʂɂ���Ă͂P���ł͏I���Ȃ����炢��ς�������܂���B
�厖�ȃf�[�^�̏ꍇ�͖������������Ǝ҂ɂ��܂������鎖���I�����Ƃ��ĖY��Ȃ��ł��������B
���ƁA�L�^������SMR��HDD�͑I�Ȃ����������ł��̂ł��C�����������B
�����ԍ��F24359193
![]() 1�_
1�_
������0220����
������������܂����ˁB�t�����g�p�l���̃L�[�iAS-604T�j�B
�����Ă݂����̂́A�c�O�Ȃ��甽���͂���܂���ł����B
�悤�₭�T�|�[�g����͂��������̂́A�i�n���O�A�b�v���Ă���̂łǂ�������ǂ��������₵�Ă���ɂ��ւ�炸�jDSM�̃��|�[�g�𑗂�ƌ����܂����B���̏�Ԃłǂ������DSM�̃��|�[�g�𑗂�̂����⒆�ł����A����܂���B�i�܂�5���ԂقǑ҂������̂����j
�����T�|�[�g�͒��߂ēd���{�^���̒����������������Ǝv���Ă��܂��B
���̌������x�i���x�̓n���O�A�b�v���Ȃ��悤�ɕ����I�ȁj�o�b�N�A�b�v���s���\��ł��B
�ň��̏ꍇ�ł�LinuxPC�ŃT���x�[�W�\�Ƃ̂��ƁA���S���܂����B
ASUSTOR��NAS���w�������͖̂{�̂��̏Ⴕ�Ă�HDD��V➑̂Ɉڂ������Ŏg����Ƃ�����`�����������Ƃ����R�Ȃ̂ł����A�T�|�[�g�����ꂾ�ƐV�K�w�����S�O����ł��B
# ���J�ȃA�h�o�C�X���肪�Ƃ��������܂��B�p�ɂɍX�V����̂ŁA���_CMR�ł��B
�i�Ď��J�����Ȃǂ̕ۊǐ�p�ł����SMR�ł��ǂ��̂�������܂���j
�ȏ��낵�����肢���܂��B
�����ԍ��F24360413
![]() 0�_
0�_
��KA-7300����
�������Ă݂����̂́A�c�O�Ȃ��甽���͂���܂���ł����B
��`�c�O�B���S�ɉ������Ȃ����Ă܂��ˁB
���悤�₭�T�|�[�g����͂��������̂́A�i�n���O�A�b�v���Ă���̂łǂ�������ǂ��������₵�Ă���ɂ��ւ�炸�jDSM�̃��|�[�g�𑗂�ƌ����܂����B���̏�Ԃłǂ������DSM�̃��|�[�g�𑗂�̂����⒆�ł����A����܂���B�i�܂�5���ԂقǑ҂������̂����j
�c�O�ȃT�|�[�g�ł��ˁBDSM����Synology?�c ^^;
�������T�|�[�g�͒��߂ēd���{�^���̒����������������Ǝv���Ă��܂��B
�����̌������x�i���x�̓n���O�A�b�v���Ȃ��悤�ɕ����I�ȁj�o�b�N�A�b�v���s���\��ł��B
���̃o�b�N�A�b�v�͌l�I�ɂ͂����߂��܂���B�܂��s�ǃZ�N�^�̕����Ŏ~�܂�\�����傫���ł��B
�����Ă�����HDD(Disk2?)������Ȃ�A�X�y�A��HDD(�����p�ӂł��Ă���)�ɃZ�N�^�R�s�[���ăf�[�^���X�g�ɔ����܂��B
�����āA�R�s�[����HDD�Ǝc���Disk1�ADisk3�ŋN���e�X�g����̂��Ó��ł��B
���̏ꍇ�A�s�ǃZ�N�^�ɓ��������t�@�C���̓R�s�[�o���܂����ꕔ�f�[�^���j�������܂܂ƂȂ�܂��B
�A�v���ɂ���Ă͐���Ɉ����Ȃ��Ȃ��Ă��܂��܂��̂ł����ӂ��������B
�����ԍ��F24360503
![]() 0�_
0�_
������0220����
���w�E���肪�Ƃ��������܂��B�m����DSM�ł͂Ȃ��AADM�ł��B�i��������������Ă܂��j
����ɂ��Ă��A����0220����͑�ώ茘���ł��ˁB
�m���Ƀf�[�^�̈��S�ȋ~�o��ڎw���ɂ́AHDD�̃o�b�N�A�b�v���擾������Œ��ނׂ��ł��B
�o�b�N�A�b�v�Ȍ�̕ύX�_�����������Ȃ���A�܂��͂������z���o�����Ǝv���Ă����̂ŔY��ł��܂��B
�������s�ǃZ�N�^�Ƀq�b�g���Ȃ���A�Â��o�b�N�A�b�v�f�[�^�ƕ����T�N�b�Ƌ~�o�����ɂȂ�̂ŁB
�����̏ꍇ�A�s�ǃZ�N�^�ɓ��������t�@�C���̓R�s�[�o���܂����ꕔ�f�[�^���j�������܂܂ƂȂ�܂��B
RAID1�̕Б����̂ł����Ȃ�܂���ˁB
�����A����������Ă����|�́A�n���O�A�b�v�������ɑS�f�[�^�����S�ɓǂݏo�����@���������������Ɨ������Ă���܂��B
���Y�Z�N�^���Ǘ����Ȃǂ�ێ����Ă���̂łȂ���ANAS�̑S�t�@�C���ɑ��ċ͂�1�t�@�C���A������X�ɂ��̃t�@�C������1�Z�N�^���̃f�[�^���������ōςޖ�ł��ˁB
# �Z�N�^�ԍ�����͂���ƁA���Y�t�@�C�����������Ă����\�t�g���؎��ɗ~�����ł��B
�@�ǂ̃t�@�C��������낤�B���ꂪ�킩��Ȃ��ƁA���\�v���I�ł��B
���Ȃ݂ɁA���̓�������҂��Ă��܂����B
-----
�璷���̂���A���C�ł͑�G�c�Ɍ����Ɠ����f�[�^�� 2�����Ԃł��B
�����A����̃f�[�^��ǂݏo�����ɃG���[�����������ꍇ�ARAID �R���g���[���͂�������̃R�s�[����f�[�^��ǂݏo���z�X�g�̗v���ɓ����܂��B
-----
�L����RAID�J�[�h�ł̃G���[�R�[�h�ɂ��āAdospara���쐬���ꂽFAQ����́i���ӓI�ȁj�����ł��B
�ihttp://faq3.dospara.co.jp/faq/show/788?site_domain=default�j
ASUSTOR��Linux�x�[�X�ŏ����M���Ă���Ɖ����̏Љ�L���œǂ݂܂����̂ŁA���̂��炢�̓���͂��Ă���Ȃ����Ȃ��ƁB
�i�n���O���܂�������ǁj
�������̋@�\�i��ASUSTOR��ADM�ɂ��邩�ǂ����͕s���ł����j�Ɋ��҂���ꍇ�AHDD�̃f�[�^�𐳏��HDD�ɃR�s�[���Ă��܂��ƁA�G���[�Ƃ��Ă����Е��̃f�B�X�N�ɓǂ݂ɂ����Ȃ��Ȃ��Ă��܂��̂ŁA����܂��Y�܂����ł��B
�����₵�Ă悭�l���Ă݂܂��B
�A�h�o�C�X���肪�Ƃ��������܂��B
�����ԍ��F24360739
![]() 0�_
0�_
��KA-7300����
�����w�E���肪�Ƃ��������܂��B�m����DSM�ł͂Ȃ��AADM�ł��B�i��������������Ă܂��j
��������������ł����� ^^
���o�b�N�A�b�v�Ȍ�̕ύX�_�����������Ȃ���A�܂��͂������z���o�����Ǝv���Ă����̂ŔY��ł��܂��B
���������s�ǃZ�N�^�Ƀq�b�g���Ȃ���A�Â��o�b�N�A�b�v�f�[�^�ƕ����T�N�b�Ƌ~�o�����ɂȂ�̂ŁB
�S�z�Ȃ̂́A���̍ŋ߂̃t�@�C���ȊO�����v�Ȃ̂��H�ł��ˁB
�R�s�[���Ɏ~�܂��Ă��܂����̂ŁA�o�b�N�A�b�v�Ȍ�̃t�@�C���ɕs�ǃZ�N�^������\���͍����̂ł���
�t�@�C���V�X�e��(Ext4�Ƃ�Btrfs)�ɂ�inode(�A�C�m�[�h)�Ƃ��Ǘ��̈悪����A�A�������Z�N�^�܂�f�Љ������e���Ă���Ȃ��ꍇ������܂��B
�s�ǃZ�N�^��Reallocate����Ă��t�@�C���V�X�e���̏C�����K�v�ƂȂ�ꍇ������܂��B(�t�@�C������f�B���N�g���c���[�Ƃ��̓f�[�^���ƕ�������Ă��܂��B)
��# �Z�N�^�ԍ�����͂���ƁA���Y�t�@�C�����������Ă����\�t�g���؎��ɗ~�����ł��B
���@�ǂ̃t�@�C��������낤�B���ꂪ�킩��Ȃ��ƁA���\�v���I�ł��B
�ȑO�Aext4��HDD�Ŏ��������ɎQ�l�ɂ����T�C�g�ł��B�imdraid�Ȃ̂ł��̎菇�ʂ�ł͂���܂���j
�s�ǃZ�N�^��@���Ēׂ� - nyacom.net
https://nyacom.net/?p=78
debugfs�͉ғ�����NAS�ł̎��s�͂����߂ł͂Ȃ��̂ŕʂ�PC��p�ӂ��܂����B
���������t�H�[�}�b�g�͉��ł���Ă��̂ł��傤�H
�Ƃ肠�����P��Âm�F���ă_���[�W�̂���t�@�C�������Ԃ��ĂȂ���A���̃t�@�C�������R�s�[���čX�V�����Ƃ�����ŐV�����f�ł��邩�Ǝv���܂��B
���L����RAID�J�[�h�ł̃G���[�R�[�h�ɂ��āAdospara���쐬���ꂽFAQ����́i���ӓI�ȁj�����ł��B
�[�ǂ݂���Ɓu�璷���̂���A���C�v�ł��̂Łc�AHDD�Q��ł�RAID1��Degraded�ɂȂ�Ə璷���͎����Ă��܂��Ă��܂��B
����͂����炭Disk2�݂̂œ��삵�Ă��Ǝv���܂��̂Łc
��Ă͂����炩����̂ł����l�ɂ���Ă͓���ꍇ������܂��B
���܂������Ȃ������ꍇ�ɑ������Ă��܂��͎̂��ł͂Ȃ�����ғa�ɂȂ��Ă��܂��܂��̂Łc
����I������̂͊e�l�̎��R�ł��̂ŁA������������ŃA�h�o�C�X���K�v�Ȏ��͂���������ĉ������B
�����ԍ��F24360861
![]() 1�_
1�_
 |
|---|
ASUSTOR�̃��O�i�n���O�A�b�v�O�j |
������0220����
�����I
�R�}���h�A����̂ł��ˁB
����͊��҂����Ă܂��B
# �Ȃ��A�t�H�[�}�b�g��ext4�������Ǝv���܂��B
����������������debugfs��ncheck���i�n���O�A�b�v���������j�g���Ă݂悤�Ǝv���܂��B
���̏ꍇ�Adebugfs�ւ̈����Ƃ��ė^���Ă���BLOCK�ԍ��́A�Z�N�^���Ɠ��ӂ̗����ŗǂ��ł��傤���B
�iicheck BLOCK �ŁA�u���b�N�𗘗p���Ă���i�m�[�h���\�������Ƃ����F���ł��j
�O�̂��߁AADM�ł̃V�X�e�����O������\���Ă݂܂��B�imedia error on sector xxxxxxx�j
����xxxxxxx��BLOCK�Ƃ��Ďw�肵�ėǂ����Ƃ����_���悭�������Ă���܂���B
���Ǝ��̐����s���Ō���������Ă��镔��������悤�Ȃ̂ŁA�ꕔ�ߑ����܂��B
�E�P�Ȃ�RAID1�Ȃ̂ŁA����ASUSTOR�̊O���ɕ����I�ȃo�b�N�A�b�v���i1�����قǑO�Ɂj�擾�ς݂ł��B
�E�����MediaError�������A�O�Ƀo�b�N�A�b�v�������������ŃR�s�[�����ق����������낤�ƁA
�@����ASUSTOR����Volume2 (6TB)����Volume1 (14TB)�փR�s�[�����{���A�r���Ńn���O�A�b�v���Ă��܂��B
�E�Ȃ̂Ńo�b�N�A�b�v�̎w�����̂�2����̂Ő����������������ƁA
�@�O���o�b�N�A�b�v�Ȍ�ɍX�V���ꂽVolume2�́i�����炭���������͖������Ƃ��肤�j�f�[�^���z���o����
�@�O���o�b�N�A�b�v�ƃ}�[�W���邱�ƂŁA�n���O�A�b�v���Ă��܂����o�b�N�A�b�v�̑�ւƂ��邱�Ƃ�����
�@�ژ_��ł��܂��B
�E���̌�A�X�V���̓��肵���˂ɔ����AVolume2�̏C�����s����Ɗ���Ă܂��B
�@�i�C�����@���Ȃ��ꍇ�́A���ē����������@��Volume2�������Adebugfs,ncheck�œ��Y�t�@�C�����p�[�W�j
�����o�b�N�A�b�v�Ȍ�̍X�V����ڎ��œ���ł���̂��A�����͍X�V�����Ō������|���Ă��̂܂܃n���O�A�b�v���Ȃ����A
�������͂��������A�h�o�C�X�������悤�ɂ܂��̓o�b�N�A�b�v���擾���Ă����ׂ����i�Y�ނ܂ł��Ȃ����ׂ��Ȃ̂ł����A
6TB×2�{�̏��v���ԁ{�X�Ȃ邨���z�ւ̕��S�ƁA��L�̎�y���Łj���߂��˂Ă��܂��B
# ����͎����Ō��߂�ׂ����ƂȂ̂ŁA������ʂ��L���܂��B
�S���̎G�k�ł����A�F�l�ɂ͎��ȐӔC�łƌy�������܂����A���܂�e�����Ȃ��l�Ɏ��ȐӔC�łƂ͌����ɂ�����������܂��B
��������܂��������@�͂Ȃ����Ǝv���Ă���܂������A�f���炵���`�����ł��ˁB�Q�l�ɂ����Ă��������܂��B
�����ԍ��F24361124
![]() 0�_
0�_
��KA-7300����
���݂��n���O�A�b�v�����܂܂��Ǝv���܂����AHDD�̓J�b�R���A�J�b�R�����Ă�
16�����炸���Ƃ��̏�Ԃ�������A�_���[�W�������Ȃ��ĂȂ������S�z�ȂƂ���ł��B
�����̏ꍇ�Adebugfs�ւ̈����Ƃ��ė^���Ă���BLOCK�ԍ��́A�Z�N�^���Ɠ��ӂ̗����ŗǂ��ł��傤���B
Block�Ƃ����̂�Windows��NTFS�ł����N���X�^�[�ɂ�����p��ɂȂ�܂��B
debugfs��icheck�ւ̈�����Block�ɂȂ�܂��̂ŁAHDD�̑f������
��(123631985 - 2048) * 512 / 4096 = 15453742.125
�ƎZ�o�������̂������Ƃ��ē��͂��܂��B
�ŁA���݂܂������o���ɂȂ��Ă��܂��̂ł����c�i�ߋ��̋L�^���ǂ��ɕۊǂ����̂��A���̋L�������ł܂��āc�j
�Q�l�F�A�������k�R��: 3�� 2021
https://ttgcameback.blogspot.com/2021/03/?m=0
�������badblocks�R�}���h���g���ĕs�nj�����肵�Ă܂��B����6TB����15���Ԃقǂ����邩�Ǝv���܂��B
������Ă����������̂́A��L�Ɖ��L(�p��)���Q�l�ɂ���ddrescue(GNU ddrescue)�R�}���h�ŃN���[�������Ȃ���
����log����s�ǃZ�N�^����肵�āAdebugfs�Ńt�@�C������肷��Ƃ������@�ł��B
�v�Z�̎Q�l�FBatch processing a ddrescue mapfile with debugfs - Unix & Linux Stack Exchange
https://unix.stackexchange.com/questions/473453/batch-processing-a-ddrescue-mapfile-with-debugfs
ddrescue�ł́A�ǂݍ��߂Ȃ������Z�N�^��log�Ƃ��Ďc�����Ƃ��ł��܂��B
Ext4�ł͖����̂ł������s���́��݂����ɂȂ�܂��B
root@ubuntu:~# ddrescue -f -n -v /dev/sdb \
> /dev/sda \
> /media/ubuntu/boot/rdn_log/rdn_dd_logfile_20210220.txt
GNU ddrescue 1.23
About to copy 5000 GBytes from '/dev/sdb' to '/dev/sda'
Starting positions: infile = 0 B, outfile = 0 B
Copy block size: 128 sectors Initial skip size: 97792 sectors
Sector size: 512 Bytes
Press Ctrl-C to interrupt
ipos: 19345 MB, non-trimmed: 0 B, current rate: 10112 B/s
opos: 19345 MB, non-scraped: 3072 B, average rate: 106 MB/s
non-tried: 0 B, bad-sector: 1024 B, error rate: 128 B/s
rescued: 5000 GB, bad areas: 2, run time: 13h 48s
pct rescued: 99.99%, read errors: 3, remaining time: 1s
time since last successful read: 0s
Finished
�P��ڂ͓ǂݍ��߂Ȃ��������̃��g���C�Ȃ��A�Q��ڈȍ~�͉��x�����g���C������ݒ�Ŏ��s���܂��B
�P��ڂ�log���g�����łQ��ڈȍ~�͓ǂݍ��߂Ȃ��������݂̂Ŏ��s����܂��̂Ő����ŏI���܂��B
�ŏI�I��log��
root@ubuntu:~# cat /media/ubuntu/boot/rdn_log/rdn_dd_logfile_20210220.txt
# Mapfile. Created by GNU ddrescue version 1.23
# Command line: ddrescue -f -d -r1 -v /dev/sdb /dev/sda /media/ubuntu/boot/rdn_log/rdn_dd_logfile_20210220.txt
# Start time: 2021-02-20 22:53:26
# Current time: 2021-02-20 22:54:23
# Finished
# current_pos current_status current_pass
0x481195E00 + 1
# pos size status
0x00000000 0x481195000 +
0x481195000 0x00001000 -
0x481196000 0x487E09A0000 +
�ƂȂ�status���u-�v�̍s�u0x481195000 0x00001000 -�v���s�ǂƔ���܂��B
0x481195000�̓o�C�g�ł��̂ŁA�܂�16�i����10�i�ɂ���� 19345788928
�����Sector size�ŏ��Z���܂��A19345788928/512 = 37784744
����ŕs�ǃZ�N�^�̏ꏊ������܂��̂ŁA���O�ŕ\�����ꂽ�l�Ƌ߂����m�F���܂��B
root@ubuntu:~# parted /dev/sdb
GNU Parted 1.9.0
Using /dev/sdb
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) unit s
(parted) p
Model: ATA WDC WD50EZRX-00M (scsi)
Disk /dev/sdb: 9767541168s
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name Flags
1 2048s 9766492159s 9766490112s xfs Basic data partition
2 9766492160s 9767532543s 1040384s linux-swap(v1)
����͂P�ԖڂȂ̂ŊJ�n�I�t�Z�b�g���������܂��A
37784744-2048 = 37782696
��ŁA�܂��u���b�N�ɕϊ� 37782696*512/4096 = 4722837
(xfs��BlockSize��4096�ɐݒ肵�Ă��̂�)
����Ńp�[�e�B�V�����̊J�n�ʒu�����Block���Z�o����܂����̂�
�����debugfs��icheck�Ŋm�F���܂��B
�����F��L�͌v�Z�̗�ł�xfs��debugfs�͎g���Ȃ������͂��Ȃ̂ŁA�ʂ̕��@���g�����Ǝv���܂��B
�����ԍ��F24361614
![]() 1�_
1�_
��KA-7300����
Linux���ł����AUbuntu�̃C���X�g�[�����f�B�A�ŋN�������Ď��p����̂��֗���������܂���B
Ubuntu��USB�u�[�g�ɂ��Ă͉��L���Q�l�ɂ��Ă��������B
Windows��Ubuntu�̃C���X�g�[��USB���f�B�A���쐬����
https://diagnose-fix.com/topic2-003/
Ubuntu Desktop ���{�� Remix�̃_�E�����[�h
https://www.ubuntulinux.jp/products/JA-Localized/download
����uubuntu-ja-20.04.1-desktop-amd64.iso�iISO�C���[�W�j�v��DL�����������B
�o�[�W�����ɂ���đ��������܂����A��{�I�ȑ���͂킩�邩�Ǝv���܂��̂ŁA�Q�l���x�ɁB
Ubuntu 18.04 LTS�̊�{�I�Ȏg����
https://sicklylife.jp/ubuntu/tsukaikata/usage.html
USB����̋N�����@��PC�ɂ����UEFI setup�Ȃǂ̕ύX���K�v��������Ƃ���Ǝv���܂��B
�T���x�[�W����ꍇ�́A���̃f�B�X�N�͌���đ��삵�Ȃ��悤�ɊO���ꂽ��������ł��B
USB����N����uUbuntu�������v�ŊJ�n���鎖���o���܂����A�ċN����ɂ̓��Z�b�g����܂��̂ł����ӂ��������B
Ubuntu�̃C���X�g�[��USB�ɂ̓t�@�C���Ȃǂ̕ۑ�������ł��̂ŁA���O����p�ɂ����P����ƕ֗��ł��B
���m�F�o����悤�ɂȂ�Ȃ��Ɣ��f������Ǝv���܂��B
�Ƃ肠�����K�v�����ȏ��Ƃ��Ēu���Ă����܂��̂ŁA�Q�l�ɂȂ�Ǝv���܂��B
�����ԍ��F24361713
![]() 1�_
1�_
������0220����
NAS���n���O�A�b�v���畜�A�����āA���ݐ�^�������ł��B
�Ƃ͂����A�����J�ɂ����������������肪�Ƃ��������܂��B
�܂��͌��\���グ�܂�
���̂悤�ȏׁ̈A�ߓǂ݂ŋ��k�ł����ARAW�ł̃R�s�[�܂�Linux�Œʏ��dd���s���Ƃ��낻�ꂾ�ƃG���[�Z�N�^�Ŏ~�܂邩�Ⴕ���̓G���[�����đS���˂����邩�ɂȂ��Ă��܂��̂ŁA�G���[�ӏ����L�^���Ȃ���dd���s���c�[�������Љ�������̂Ɨ������Ă��܂��B�܂��v�Z�����ۂɍs���Ă��������ď�����܂��B�܂��������ǂ��t���Ă��Ȃ��̂ŁA�����̂𗝉����Ȃ��Ă͂Ȃ�܂��A�ȈՂɎg�킳���Ă����������Ǝv���Ă���܂��B
�@�ǂ����I�m�Ȃ��ԐM���Ă���Ȃ��Ɣ��X�v���Ă͂����̂ł����A���o���ҁi���H�ҁj�Ȃ̂ł��ˁBLinux�iUbuntu�j�̎g�p�J�n���@���܂߁A�M�d�ȃA�h�o�C�X�Q�l�ɂȂ�܂��B
�b���߂�܂����A���ݍ������Ă���̂́A�����ڏ�́u�����āv���܂�������ł��B
���ꂩ��Ƃ��Ƃ��A�d���{�^�������������{���Ă��܂��܂����B���̃L�[�͔�������܂��A���̎�@�̓n�[�h�E�F�A�I�ɏ��������̂��A���Ȃ��d������܂����B
���̌�V�X�e���iNAS�j�͖����N�����A��Ԃ��m�F�����Ƃ���RAID�{�����[��1,2�F����AHDD�idrive1�`4�j�F����ƁA��킩��܂���B
�ǂ��b�ł͂���̂ł����AMediaError�ŏ璷���������Ȃ�������RAID1�{�����[�����u�璷��1�h���C�u�v�����邱�ƂɂȂ��Ă��܂��B
�����ŁA����������cat /proc/mdstat�������������������Ȃ��Ǝ��{���Ă݂܂����B�iSSH�̓f�t�H���g�����ł����̂ŗL���ɂ�����Łj
-----
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid1 sdb4[0] sdd4[1]
5855934464 blocks super 1.2 [2/2] [UU]
md1 : active raid1 sda4[2] sdc4[3]
13667923968 blocks super 1.2 [2/2] [UU]
[>....................] resync = 0.0% (10368384/13667923968) finish=23746.6min speed=9585K/sec
md126 : active raid1 sda3[6] sdd3[5] sdb3[4] sdc3[7]
2096064 blocks super 1.2 [4/4] [UUUU]
md0 : active raid1 sdc2[7] sdd2[5] sdb2[4] sda2[6]
2096064 blocks super 1.2 [4/4] [UUUU]
-----
�s���́A�ǂݎ��������Ă��܂��A���炩��resync�������Ă��܂��B
GUI�̉�ʕ\����������x�m�F����ƁA�̏Ⴕ�Ă��Ȃ���������volume1�͓����������ł����B
�l���Ă݂�Avol2����vol1�փf�[�^���R�s�[�i�������݁j���Ƀn���O�A�b�v�����̂ŁA�܂����R�ł͂���܂��B
���������volume1�͓�����҂Ă��̂܂g����Ƃ��āAvolume2�͐��툵���ƂȂ��Ă�����̂́A�f�[�^�����������ǂ����̋^�O���c��܂��B�����Łi����܂������������������jdebugfs���iNAS��Łj�@���Ă݂܂������Anot found�ł����B�X�V���̓��X�g���Ă��\��Ȃ��f�[�^�ł����̂ŁA�o�b�N�A�b�v����S���X�g�A���ׂ�����Y�ݒ��ł��B�����ASUSTOR���g�������Ă䂭�̂ł���A1�Z�N�^�i��������2�Z�N�^�j���̃f�[�^���������ǂ����������ׂ��Ȃ̂ł����B
# �����Â��ŁA����ł���HDD�������ĔM���Ȃ炸�AASUSTOR��➑̎��̂͑�ϋC�ɓ����Ă��܂��B
�@�����T�|�[�g�̖������̂��g��������C�͂��Ȃ��̂ŁA����ǂ����邩���������Ȃ��Ă͂Ȃ�Ȃ��Ȃ�܂����B
�@��RAID5�Œɂ��ڂɂ������̂�RAID1�ɂ��Ă����̂ł����A�����RAID6�ɂ���ׂ���������܂���B
�@�iHDD�̑�e�ʉ����i��ł����̂ŁA�������͒P��single�h���C�u���ڑ��Ƃ��邩�Y�݂܂��B
�@�@RAID1�ő唼�������c���Ă��Ă��f�[�^�������Ă��邩�Y�ނ̂ł���Asingle�̕����}�V�Ȃ悤�ȁj
�Ȃ��ӊO�Ȃ��Ƃ�S.M.A.R.T.��Reallocated_Sector�l�͑S��0�ł����B���������
----------
Disk1 Disk2 Disk3 Disk4
Raw_Read_Error_Rate 0 0 0 51
Reallocated_Sector_Ct 0 0 0 0
Reallocated_Event_Count 0 0 0 0
Current_Pending_sector 0 0 0 0
Offline_Uncorrectable 0 0 0 0
----------
�Ƃ��������ŁADisk4�͂��낻��Z�N�^��֏��������肻���ł��B�i���_�A��������Ɍ������܂��j
�ȏ�Ƃ�Ƃ߂Ȃ��ł����A������L���Ă݂܂����B
�iRAID1���������A�Ƃ��������n���O�A�b�v�ŊǗ������ꂽ��������܂��j
�����ԍ��F24362867
![]() 0�_
0�_
��KA-7300����
���͂悤�������܂��B
�����Ȃ��d������܂����B
�Ȃ�Ƃ���܂������A�X�C�b�`��NG�ŃR���Z���g���狃�������u�`�b�Ɓc�Ƃ�����������܂����A����͔�����ꂽ�݂����łȂɂ��ł��B
�ŋ߂̓d���X�C�b�`�̓��[�����^���X�C�b�`�Ŏ��ȕێ���H�������Ă�Ǝv�����ǃ��Z�b�g�������Ȃ��Ȃ�Ă̂����܂ɂ��邻���ł��B
SSH�̃|�[�g��22�ȊO�ɂ��邩�A�g��Ȃ��Ƃ��͖����ɂ��Ă����������Z�L�����e�B�I�Ɉ��S�ł��B
Tera Term�̃L�[�{�[�h�V���[�b�g�J�b�g�́A�R�s�[��Alt+C�A�y�[�X�g��Alt+V�ł��B
Ctrl+C��Break(���f)�ɂȂ�܂��B�����ݒ肾�ƃ}�E�X�E�N���b�N���y�[�X�g�ɂȂ��Ă�̂Ō둀��ɂ͂����ӂ��������B
�������ŁA����������cat /proc/mdstat�������������������Ȃ��Ǝ��{���Ă݂܂����B
root@NAS220J01:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md3 : active raid1 sdb3[0]
5855700544 blocks super 1.2 [1/1] [U]
md2 : active raid1 sda5[0](E)
239367424 blocks super 1.2 [1/1] [E]
md1 : active raid1 sda2[0] sdb2[1]
2097088 blocks [2/2] [UU]
md0 : active raid1 sda1[0] sdb1[1]
2490176 blocks [2/2] [UU]
�ʃ��[�J�[�ł��������ŃN���b�V�����������́��݂����Ȋ�����(E)��[E]�̂悤��Error�Ɣ��銴���������̂ł���
�����̂ŁAFalt�ƃ}�[�N�܂ł����ĂȂ������݂����ł��ˁB�u�璷��1�h���C�u�v���̕\���̐M�ߐ����Ȃ��ł��ˁB
���ɂO�ł��璷�\�����ێ������Ă�Ȃ畴��킵���ł��ˁAJARO�ɂł����k���܂��� ^^;
���āA�ċN������RAID�A���C���ǂݍ��܂ꂽ�^�C�~���O��disk1��disk3��superblock���`�F�b�N�łЂ����������Ǝv���܂��B
������ɏ����݂��Ă����Ƀn���O�����̂Ń^�C�~���O�����������Ƃ����c
mdadm -D /dev/md1
�� D :Detail --detail�Ɠ���
��sync�̕����͊m�F�ł���Ǝv���܂��B
finish=23746.6min�ł����A�����ł��ˁB����ɃV���b�g�_�E���o���Ȃ������̂Ńt�@�C���V�X�e��(Ext4)�̃`�F�b�N���������Ă邩������܂���̂ŁA���炭�͕��ׂ����܂肩���Ȃ���������ł��ˁB
��debugfs���iNAS��Łj�@���Ă݂܂������Anot found�ł����B
root@NAS220J01:~# env | grep PATH
PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/syno/sbin:/usr/syno/bin:/usr/local/sbin:/usr/local/bin
root@NAS220J01:~# which debugfs
/sbin/debugfs
PATH���ʂ��Ă�����udebugfs�v�Ŏ��s�ł��܂����APATH���ʂ��Ă��Ȃ��ꍇ�́u/sbin/debugfs�v�Ɛ�p�X�œ��͂���K�v������܂��B
which�R�}���h��PATH���ʂ��Ă���A�ǂ��ɂ��邩�������Ă���܂��B
ADM�ɂ�debugfs�������ĂȂ���������܂���B(�O�O���Ă݂����ǂ���炵���̖����ł��B)
�\������������O����
slot4(Disk4) �F1011768�Z�N�^
slot2(Disk2) �F1080464�Z�N�^
�ł̒ʒm�������Ǝv���̂ł����A�ꉞ�̊m�F�͂��������悢�̂�S.M.A.R.T.��log�����������������ǂ��ł��傤�B
1�Z�N�^512�o�C�g���ƁA
Disk2��553197568�o�C�g = 527.5703125MiB
Disk4��518025216�o�C�g = 494.02734375MiB
���Ȃ�HDD�擪�̕����ƂȂ�܂��B
parted -s /dev/sdb unit s print
��
parted -s /dev/sdd unit s print
�Ń��O�̃Z�N�^�����Ԗڂ͈̔͂��m�F���Ă݂Ă��������B�uNumber�v���S�ȊO����OS�֘A�̃p�[�e�B�V�����Ŕ��������Ǝv���܂��B
OS�֘A�ł���ƁA���ꂪ�n���O�A�b�v�Ɏ������v���ł͂Ȃ����Ƃ��c
�i�͂₭�C�Â�����I�Ƃ����܂ꂻ���ł����A�������Ă���ł���c�j
���̃��X�ɑ����c
�����ԍ��F24363210
![]()
![]() 1�_
1�_
�����Ȃ��Ď��߂���Ȃ������̂ő����ɂȂ�܂��B
�ꉞ�A���ɔg�y���ĂȂ����̊m�F�B
root@NAS220J01:~# which smartctl
/bin/smartctl
�Ŏg����悤��������
smartctl -a /dev/sdx
�� sdx�Fx��a�`z�A�Y���h���C�u�̃f�o�C�X�ɍ��킹��B
log���L�^����ĂȂ����͉��L�݂����ɂȂ�A�G���[���������炻�̓��e���L�^����Ă���ꍇ������܂��B
SMART Error Log Version: 1
No Errors Logged
�����Ă���������O�Ɂu[Disk Docter] S.M.A.R.T. quick scanning of...�v�Ƃ���̂�
S.M.A.R.T.�̃V���[�g�e�X�g���X�P�W���[�����}�j���A���Ŏ��s����Ă�̂�
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed: read failure 90% 48910 37784744
�ƃ��O�������邩������܂���B
icheck�ւ̈����̌v�Z�́A
�Z�N�^��4k�l�C�e�B�u��HDD�ȊO��512�o�C�g�ł̌v�Z�ő��v���Ǝv���܂��B
Block size�̒��ו��́A��������tune2fs�͂���Ǝv���܂���
root@NAS220J01:~# which tune2fs
/sbin/tune2fs
tune2fs����Ή��L�̂悤�Ƀ{�����[���Q�u/dev/md2�v���w�肵�Ċm�F�ł���Ǝv���܂��B
tune2fs -l /dev/md2 | grep -i "block size"
LVM�g���Ă�̂Ńp�X�͈Ⴂ�܂�������Ȋ�����
root@NAS220J01:~# tune2fs -l /dev/vg1000/lv | grep -i "block size"
Block size: 4096
�{�����[���Q�̃t�@�C���V�X�e����̊J�n�Z�N�^(Start sector)�͉��L�ł܂�RAID�A���C��Start�Z�N�^���m�F�i0s���Ǝv���܂����j
parted -s /dev/md2 unit s print
�A���C��/dev/sdb4��/dev/sdd4�ł��̂ŁA��قǂ̌��ʂ�����Start�Z�N�^���m�F��
Start sector = [/dev/md2�̊J�n�Z�N�^] + [/dev/sdb2��sdd4�̊J�n�Z�N�^]
�ƌv�Z���܂��B
smartctl��LBA����͑O��̎��Q�l��
��(123631985 - 2048) * 512 / 4096 = 15453742.125
Block = ([LBA] - [Start sector]) * [Sector size] / [Block size]
= ([LBA] - [Start sector]) * 512 / 2048
�ƂȂ�܂��B
���O�ɕ\�����ꂽ�Z�N�^�ԍ�(��LBA)����ł���L�Ɠ����ɂȂ�܂��B
linux�̕s�ǃZ�N�^�`�F�b�N�̓c�[���Ƃ���badblocks���悭�g���Ă��܂��B
���������̃f�[�^�������Ԃł́A��j��`�F�b�N���w�肵�Ă��S�z�Ȗʂ͂���܂��̂ʼn^�p���͎��s���Ȃ������ǂ��ƌl�I�ɂ͎v���܂��B
����̌�����/dev/md0�Ŕ������Ă�̂ł͂Ƌ^���Ă��܂����Aresync���łȂ����NAS���V���b�g�_�E������
��PC��/dev/md0�⑼�̃p�[�e�B�V�������`�F�b�N�������߂������Ƃ���ł��B
�����ԍ��F24363218
![]() 1�_
1�_
���݂܂���A��L�����ɂȂ�܂��B
×:/dev/sdb2 -> ��:/dev/sdb4
[��]
�A���C��/dev/sdb4��/dev/sdd4�ł��̂ŁA��قǂ̌��ʂ�����Start�Z�N�^���m�F��
Start sector = [/dev/md2�̊J�n�Z�N�^] + [/dev/sdb2��sdd4�̊J�n�Z�N�^]
�ƌv�Z���܂��B
[��]
�A���C��/dev/sdb4��/dev/sdd4�ł��̂ŁA��قǂ̌��ʂ�����Start�Z�N�^���m�F��
Start sector = [/dev/md2�̊J�n�Z�N�^] + [/dev/sdb4��sdd4�̊J�n�Z�N�^]
�ƌv�Z���܂��B
×:2048 -> ��:4096
[��]
Block = ([LBA] - [Start sector]) * [Sector size] / [Block size]
= ([LBA] - [Start sector]) * 512 / 2048
[��]
Block = ([LBA] - [Start sector]) * [Sector size] / [Block size]
= ([LBA] - [Start sector]) * 512 / 4096
�����ԍ��F24363575
![]() 1�_
1�_
������0220����
�Z�L�����e�B�ցiport�ԍ��j�̔z���ɂ��Ă������L��������܂��B�ꉞ����@�ȊO�̑�IP�͒e���悤�ɂ��Ă��܂��B
�c�O�Ȃ���debugfs��/sbin�ɂ��Ȃ��A�������܂���ł����B
����͂����ƁA���w�E�̓h���s�V�����Ȃ悤�ȋC�����܂��B
-----
# parted -s /dev/sdb unit s print
Model: ATA HGST HDN726060AL (scsi)
Disk /dev/sdb: 11721045168s
Sector size (logical/physical): 512B/4096B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 2048s 524287s 522240s
2 524288s 4718591s 4194304s raid
3 4718592s 8912895s 4194304s raid
4 8912896s 11721043967s 11712131072s raid
-----
Disk2��media error�̓Z�N�^1080464�ŋN�����̂ŁA��L���ʂ��炷��Ɨ̈�No.2���Ŕ������Ă���Ƃ������Ƃł��傤���B����Disk2��4��1��RAID1�ɂ��Ă���̂ŁA����h���C�u����RAID�p�[�e�B�V������3����̂��ǂ��������Ƃ��iLinux�̎d�g�ݎ��̂��j�悭�������Ă���܂���B��ԃT�C�Y�̑傫��4�Ԗڂɂ͊Y�����Ă��Ȃ��̂Ńf�[�^�������Ƃ��Ă��ANumber2��3�̗̈悪���Ȃ̂����s�v�c�ł��B
�m���s���́A�����������������㔼�����ɂ͂܂�����o���Ă��܂���B
�ȏ��낵�����肢���܂��B
�����ԍ��F24364546
![]() 0�_
0�_
��KA-7300����
��Number2��3�̗̈悪���Ȃ̂����s�v�c�ł��B
���̂Q�͂����炭�V�X�e���̈�Ɖ��z�������̃X���b�v�̈�Ɏg���Ă���Ǝv���܂��B
��ɂ������܂������A�f�[�^�̗̈��OS�̗̈�͕�������Ă��āA�f�[�^�̗̈�i�{�����[���j��lj�������������肵�₷������Ă��܂��B
�V�X�e��(ADM)�̒��j��rootfs�Ƃ��������肵�܂��B(Windows��C:\windows�̖����݂�����)
���L�R�}���h�ŁuMounted on�v���u/�v�ɂȂ��Ă���̂�Number2��RAID�A���C�ł����rootfs�ɂȂ�܂��B
df -h
root@NAS220J01:~# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/md0 2.3G 914M 1.3G 42% /
none 224M 0 224M 0% /dev
/tmp 243M 1.5M 241M 1% /tmp
...(�ȗ�)
�X���b�v��OS�ɂ���Ď������قȂ�̂ł������L�Ŋm�F�\��������܂���B
swapon -s
root@NAS220J01:~# swapon -s
Filename Type Size Used Priority
/dev/md1 partition 2097084 2308 -1
�����C�ɂȂ����̂ł����A
md2 : active raid1 sdb4[0] sdd4[1]
md1 : active raid1 sda4[2] sdc4[3]
md126 : active raid1 sda3[6] sdd3[5] sdb3[4] sdc3[7]
md0 : active raid1 sdc2[7] sdd2[5] sdb2[4] sda2[6]
sdb4[0]�̗l��[]���̐��l�͊e�A���C�Œlj����ꂽ���ԂŃi���o�����O�����̂ł���
��U�A���C����remove�����ƁA���̔ԍ��͌��ԂɂȂ蓯��HDD�ōēx�lj����Ă��ԍ����ς��͂��Ȃ̂�
md2�ȊO�̃A���C�͑S��1��remove���ꂽ�����Ɏv���܂��B
����md1��resync�̍Œ����Ǝv���܂����A�R�}���h�Ŋm�F����ȑO��md0��md126��resync����Ă��\�����l�����܂��B
�����A�A���C���̃t�@�C���������g�p���̏ꍇ�A���C���~���鎖��remove����t�������͂��Ȃ̂ʼn����N�������̂��s�v�c�Ȋ��������܂��B
���ƁA�t�@�C���̔�r��openssl�R�}���h���g����ꍇ��SHA256�n�b�V���ȂǂŊm�F���Ă��܂��B
�s�ǃZ�N�^�ɂ��������t�@�C���̓R�s�[���̎��s���Ă��܂���������̂ŁAddrescure�g������̊ȈՔ�r�ɂ͎g���邩�ȁH
root@NAS220J01:~# openssl sha256 /var/services/homes/taku/openvpn.log
SHA256(/var/services/homes/taku/openvpn.log)= 55c593799c16523d09e28eaff314849bf3f598235a2e8799004bcabf6cc78856
Windows����7zip�Ƃ��ł�SHA256�͊m�F�ł��܂��ˁB
ddrescure�̓N���[�������ݓI�ȕs�ǃu���b�N�̊m�F�Ƃ��̋L�^���ł���̂ŕ֗��ł���Ƃ������ł��B
�V�X�e���ɒʒm����Ė��������̏ꍇ������܂��̂ŁB
Raw_Read_Error_Rate�͍ċN�������RAW_VALUE�̓��Z�b�g�����0�ɂȂ����Ǝv���܂��̂�
VALUE�AWORST�ATHRESH�̍��ڂ�����WORST(�ň��l)��THRESH�ȉ��ɂȂ��ĂȂ������m�F���Ƃ�����������Ǝv���܂��B
�����ԍ��F24364815
![]() 1�_
1�_
������0220����
����Ă���̂ł͂Ȃ����A�Ǝv���悤�ȏɂȂ�܂����B
�o�b�N�A�b�v���ǂݏo���܂���B
���m�ɂ́A����ASUSTOR�Ƃ͕ʂɁAHP��MicroServer(N36L)�ō\�z����NAS�փo�b�N�A�b�v��ۑ����Ă��܂����B����܂œǂ߂Ă����̂ł����A����N36L�̓d��������܂���i�{�����F����ΐF�ɂȂ锤���A���F�̂܂܁j�B�Ɨ��@�\�ł���MicroServer��RemoteAccessCard�̂ݐ����Ă��āA�d���R���g���[����ʂ͕\���������̂́i���R�Ȃ���j�d���͓��炸�A�����������܂��BN36L�ɂ�HardwareRaidCard�����Ă����̂ŁARaid5�̓ǂݏo�����ʏ��HDD��葁���C�ɓ����Ă��������Ɏc�O�ł��B���Ȃ݂�HP��N36L��ASUSOTR��AS-604T�Ƃ�������ł��i�{�b�N�X�^�ŁA�����Ƀ��o�[����HDD�x�C��4�䕪�j�B
�悭�悭�l���Ă݂�AN36L���Â��Ȃ��Ă����i����3Ware�̃T�|�[�g���j�̂�ASUSOTR���w���������Ƃ��l����ƁA���̏Ⴕ���̂��s�v�c�ł͂Ȃ��̂�������܂���B�����A����ASUSTOR��RAID1�����������Ȃ������̃^�C�~���O�ʼn���̂��Ƃ͎v���܂����B
���݃o�b�N�A�b�v��0�ɂȂ��Ă��܂����̂ŁA�{����ASUSTOR��HDD�ƌ������悤�Ǝv���ď�������HDD�ցA�f�[�^�z�o�����ł��B
���āA�̐S��d�̌��ʂ�
Filesystem Size Used Avail Use% Mounted on
rootfs 480M 68M 413M 15% /
tmpfs 494M 184K 493M 1% /tmp
/dev/md0 2.0G 360M 1.5G 20% /volume0
/dev/loop0 951K 13K 918K 2% /share
/dev/md1 11T 7.4T 3.5T 69% /volume1
/dev/md2 5.5T 4.9T 564G 90% /volume2
�ƂȂ��Ă���Arootfs���ĉ����H��Ԃł��B
���swapon�ɂ��Ă�-s�I�v�V�����������悤�ł��B
-----
# swapon -s
swapon: invalid option -- 's'
BusyBox v1.19.3 (2021-07-27 00:40:20 CST) multi-call binary.
Usage: swapon [-a] [-p PRI] [DEVICE]
Start swapping on DEVICE
-a Start swapping on all swap devices
-p PRI Set swap device priority
-----
�������ł��݂܂���B
# �⑫ volume1��HDD�́A�e�ʂ̑傫��HDD�Ɋ����ς݁i6TB->14TB�j�ł��B
�ȏ��낵�����肢���܂��B
�����ԍ��F24365000
![]() 0�_
0�_
������0220����
typo�ƌ�����܂����̂ŁA�ȉ��������܂��B
��F���āA�̐S��d�̌��ʂ�
���F���āA�̐S��df -h �̌��ʂ�
������ df -h �̌���
-----
Filesystem Size Used Avail Use% Mounted on
rootfs 480M 54M 427M 12% /
tmpfs 494M 40K 494M 1% /tmp
/dev/md0 2.0G 361M 1.5G 20% /volume0
/dev/loop0 951K 14K 917K 2% /share
/dev/md1 13T 3.4T 9.3T 27% /volume1
/dev/md2 5.5T 4.8T 627G 89% /volume2
-----
�܂��A���̑������������������R�}���h�̌��ʂ͎��̂悤�ɂȂ�܂����B
�Esmartctl
�@����܂����B������Ă��Ȃ��̂ŁA�ǂ�����Ȃ��悤�Ɍ����܂��B
�Etune2fs
�@/dev/md0, md1, md2 �Ƃ��� 4096 �ł����B
�@/dev/md126��
�@�@�@tune2fs: Bad magic number in super-block while trying to open /dev/md126
�@�@�@Couldn't find valid filesystem superblock.
�@�ƂȂ�܂����B
�Eparted
�@�@ Number Start End Size File system Flags
�@�@/dev/md0�@�@�@ 1 0s 4192127s 4192128s ext4
�@�@/dev/md1�@�@�@ 1 0s 27335847935s 27335847936s ext4
�@�@/dev/md2�@�@�@ 1 0s 11711868927s 11711868928s ext4
�@�@/dev/md126 �@ 1 0s 4192127s 4192128s linux-swap(v1)
�ȏ�⑫�ƂȂ�܂��B
�����ԍ��F24365161
![]() 0�_
0�_
��KA-7300����
���ƂȂ��Ă���Arootfs���ĉ����H��Ԃł��B
����H���̎�@�͎�������̏��߂ĂȂ̂Łc
�l�b�g�������m�F���Ă݂��̂ł����A������Ɣ���Ȃ��ł��B
�����swapon�ɂ��Ă�-s�I�v�V�����������悤�ł��B
-s�I�v�V�����Ȃ������ł����B
����/dev/md126���Ǝv����̂ŁA���L�ł������Ă݂Ă��������B
�ulinux-swap(v1)�v�݂�����swap���܂܂�Ă���OS�N�����ɃZ�b�g�����݂����ł��B
parted -s /dev/md126 print
root@NAS220J01:~# parted -s /dev/md1 print
Model: Linux Software RAID Array (md)
Disk /dev/md1: 2147MB
Sector size (logical/physical): 512B/512B
Partition Table: loop
Disk Flags:
Number Start End Size File system Flags
1 0.00B 2147MB 2147MB linux-swap(v1)
�Ƃ������ŏ�L�ŃX���b�v�̈�ƂȂ�����A�����@�Łu/dev/md0�v�̓V�X�e���W�Ƃ��������Ǝv���܂� ^^;
��# �⑫ volume1��HDD�́A�e�ʂ̑傫��HDD�Ɋ����ς݁i6TB->14TB�j�ł��B
�Ȃ�قǁA�����ł��B
# �s���Ⴂ�ɂȂ肻���������̂ŒNjL
���܂��A���̑������������������R�}���h�̌��ʂ͎��̂悤�ɂȂ�܂����B
parted�̌��ʂ���/dev/md126���X���b�v�ł��ˁB
�X���b�v��tune2fs�ɑΉ����Ă��Ȃ��t�@�C���V�X�e���Ȃ̂�open�o���Ȃ��Đ���ƂȂ�܂��B
S.M.A.R.T. ���ُ�Ȃ������ł��̂ŁA�ЂƂ܂�resync���I���܂ł͗l�q�݂ł��ˁB
������Ă���̂ł͂Ȃ����A�Ǝv���悤�ȏɂȂ�܂����B
�s�^���đ����Ă��܂���������܂���ˁc
�����ɋz���o����悤�A����Ă���܂��B
�����ԍ��F24365191
![]() 1�_
1�_
������0220����
���A�l�ŁA�z�o�����i�n���O�A�b�v�����j�����ɐi��ł���܂��Bmeda error�ƂȂ����Z�N�^���A�f�[�^�̈�ł͂Ȃ����ƂJ�ɂ��ē�������Ϗ�����܂����B�������\���グ�܂��B�i���������̕��͖����������܂����j
�Ȃ�����̃o�b�N�A�b�v�́A�O��̂悤��ADM��̃t�@�C���G�N�X�v���[���[�ɂ��o�b�N�A�b�v�ł͂Ȃ��A��UPC�o�R�ŕ�HDD�փR�s�[���s���Ă��܂��B����windows���g���Ă���̂ŃR�s�[�ɂ�ROBOCOPY.EXE���Ƃ����iOS�W���́j���[�e�B���e�B���g�p���Ă���܂��B��w�܂łɁALinux�œ��l�̂������߃c�[�����������������������K���ł��B
���@explorer(GUI)�ŃR�s�[������������A�����Q�Ɉ��肵�Ă��܂��B���ʂȃI�v�V�������w��ł���͖̂��_�̂��ƁA�R�s�[���Ƀ��O���o�͂���̂ŁA����R�P���ꍇ�ł���蒼���̎�|���肪�����܂��B������Linux�iubuntu�j�ɂ����l�ȃc�[��������̂��낤�Ǝv���A������ɂ͒m�����Ȃ��BADM�̃G�N�X�v���[���[�ł͂Ȃ��A�R�}���h�Œ��ɃR�s�[�o������̂ł���A�g���Ă݂����Ǝv���Ă���܂��B
�ȏ��낵�����肢���܂��B
�����ԍ��F24366865
![]() 0�_
0�_

���̌��18���̕ԐM������܂��B


NAS(�l�b�g���[�NHDD) > ASUSTOR
NAS�̃f�B�X�N�������@�ɂ��ċ����Ă��������B
ASUSUTOR��NAS�iAS3102T�j��RAID�P��g��ł��܂��B
�{�����[���P
DISK1 4GB
DISK2 4GB
�f�B�X�N�e�ʂ����Ȃ��Ȃ��������̂ŁA8GB��2�{�w��
�ȉ��̎菇��DISK2������
NAS�̓d��OFF
��
DISK2������
��
�d��ON
�č\��������A6���Ԓ��x�Ő���I��
�{�����[���P
DISK1 4GB
DISK2 8GB
�����̌�ADISK1�������������ł����A�����菇�ł悢�̂��s���ł��B
��DISK1���z�X�g�I�Ȗ��������Ă���̂ł���ADISK1������������DISK2����ɂȂ�Ȃ����ƁB
���܂��A�����������̎菇�͐������̂��H
��낵�����肢�������܂��B
![]() 0�_
0�_
���݂܂���BGB��TB���ԈႦ�܂����B
�����ԍ��F23011606
![]() 0�_
0�_
>DISK1���z�X�g�I�Ȗ��������Ă���̂ł���ADISK1������������DISK2����ɂȂ�Ȃ����ƁB
����ł�RAID1�̈Ӗ��͂Ȃ��̂ŁB
�菇�͂���ŗǂ��Ǝv���܂����B�菇���Ԉ������f�[�^�������Ă��܂��܂��̂ŁA�o�b�N�A�b�v�͂��Ă����܂��傤�B
RAID�̓o�b�N�A�b�v���蓾�܂���̂ŁB���������ړI��RAID1�ɂ��Ă���̂Ȃ�A������@��Ɏ~�߂Ă��܂��̂����肩�ƁB���̕ӂ̋L�����Q�Ƃ̂��ƁB
>RAID�̓o�b�N�A�b�v�ł͂Ȃ�(IT�G���W�j�A�ł͂Ȃ��l����)
https://2502.net/raid-is-not-a-backup/
�����ԍ��F23011673
![]() 1�_
1�_
�t�@�C���o�b�N�A�b�v����Ă���A�VHDD�y�A�ŁA
�V�K�\�z����Ȃ��ł����B
�����ԍ��F23011686
![]() 1�_
1�_
�����NAS������ғ����Ă���Ȃ�A���O����HDD��PC�Ńt�H�[�}�b�g��NAS�f�[�^���R�s�[����B
�R�s�[������I��������ANAS��4TB��8TB�ɓ���ւ���Rebuild������B
�����ԍ��F23011718
![]() 2�_
2�_
��KAZU0002����
��RAID1�̈Ӗ��͂Ȃ��̂�
�����ł���ˁB���̊m���ق����̂ł��B
��ZUUL����
NASNE�̘^��������Ƀ��[�u���Ă���̂ł��B
TV�^��t�@�C���́A�t�@�C�����o�b�N�A�b�v���ĕ����͂ł��Ȃ��ƔF�����Ă��܂��B
���ꂪ�����ɂ����̍����ł��B������Ƃ�������t�@�C���͖����ł���x�ƌ���Ȃ��Ȃ�...
�����ԍ��F23011723�@�X�}�[�g�t�H���T�C�g����̏�������
![]() 0�_
0�_
��Hippo-crates����
�^��t�@�C���Ȃ̂ł��B
�^��t�@�C���̓t�@�C���R�s�[���Ă��g���Ȃ�
�Ƃ����F���Ȃ̂ł��B
�����ԍ��F23011729�@�X�}�[�g�t�H���T�C�g����̏�������
![]() 0�_
0�_
�F���܁A���肪�Ƃ��������܂��B
������ƍQ�ĂĂ���܂��ė��M�ł��݂܂���B
���������
�@DISK1���z�X�g���ۂ����ADISK1���������đ��v���H
�A�^��t�@�C�����o�b�N�A�b�v���Ė߂��Ă����v�Ȃ̂��H
�Ƃ������ƂɂȂ�܂����A
�@��ok�Ƃ������Ƃł�낵���ł��傤���H
�����ԍ��F23011788�@�X�}�[�g�t�H���T�C�g����̏�������
![]() 0�_
0�_
������S�z�Ȃ��Ƃ�
��̌o���k�ł����CBUFFALO �� Nas �ł̗�
1TB HDD��RAID1���\�z�CHDD�̈��2TB�Ɍ����C���r���h��c���HDD�l�����C
2TBx2 RAID1�ɂȂ����� �c�O�Ȃ���e��1TB�̂܂܂�2TB�ɂ͂Ȃ�Ȃ������B
���߂āCWeb�ݒ��ʂ���t�H�[�}�b�g���邱�Ƃ� 2TB RAID1���\�z���ꂽ�I
ASUSTOR AS3102T �ł��C���l�Ȃ̂��͕�����܂��C�Q�l�ɂȂ�E�E�E�E
�����ԍ��F23011825
![]() 1�_
1�_
��������
���肪�Ƃ��������܂��B�C�ɂ����Ă܂���ł����B
��Web�ݒ��ʂ���t�H�[�}�b�g���邱�Ƃ� 2TB RAID1���\�z���ꂽ�I
�Ƃ������Ƃ́A��ł����₷���Ƃ͂ł����̂ł����H
�|���ĉ����ł��Ȃ��Ȃ��Ă��܂����B
�����ԍ��F23011968�@�X�}�[�g�t�H���T�C�g����̏�������
![]() 0�_
0�_
�ȒP�Ɍ����ƁCHDD��2TB�ɂ��ă��r���h���Ă��C�e�ʃA�b�v�ɂ͂Ȃ�Ȃ����C
�t�H�[�}�b�g������ 2TB RAID1�ɂȂ����C���R�f�[�^�[�͂Ȃ��Ȃ�E�E�E�E�ł����I
�����ԍ��F23011987
![]() 1�_
1�_
�f�[�^���������܂܂ŁA�u�e�ʂ̊g���v���ł��������B
�ȉ��̎菇�ł���Ă݂�����B(^^)/
�uasustor NAS 352 ��荂�� RAID ���x���ɃX�g���[�W�{�����[�����ڍs���A���̃X�g���[�W�e�ʂ��g�傷����@�ɂ��Ċw�ԁB�v
�u3. NAS�̗e�ʂ��g�傷��
3.1 �����̃n�[�h�f�B�X�N�����傫�ȃf�B�X�N�ɒu��������v
https://www.asustor.com/online/College_topic?topic=352#31
�����ԍ��F23012068
![]()
![]() 1�_
1�_
��Excel����
���肪�Ƃ��������܂��B
����Ȃ�ł����ǁA������S�z�������āB
�@���ł�DISK2�͂WTB�ɂȂ��Ă��邱�ƁB
�A���̎菇���悭�킩��Ȃ��āA
�@�����ւ���Ƃ���NAS���V���b�g�_�E�����Ă����̂ł���ˁH
�����ԍ��F23012082
![]() 0�_
0�_
�U�b�N���Ƃ����菇�͂����ˁA
�E���������ւ��āA�č\�z����B
�E����������A�����������ۂ�����ւ��āA�č\�z����B
�E��������ƁA�u�X�g���[�W�}�l�[�W���v�Ɂu�e�ʂ̊g��{�^���v���łĂ����ŁA�|�`���Ɗg�傷��B
���Ă��Ƃ����B
�����ԍ��F23012086
![]() 2�_
2�_
��Excel����
�����N��̎菇��
���X�e�b�v4
������ŁA�ŏ��̃f�B�X�N���������鏀���������܂����B [�X�e�[�^�X:]�t�B�[���h�ɏo��w���ɏ]���A
���f�B�X�N�����v���Z�X������ǂ��čs�����Ƃ��ł��܂��B
�����ŏ��̃f�B�X�N�̃h���C�u�g���C�����o���A
�����Â��f�B�X�N��V�����傫�ȗe�ʂ̃f�B�X�N�ɒu�������܂��B
���́��̕����́ANAS���V���b�g�_�E�����čs����ł���ˁH
�����ԍ��F23012101
![]() 1�_
1�_
���̎q�́A�u�z�b�g�X���b�v�v���ނ����������\���Ȃ�ŁA�d�����Ă���̑���ł��[��łȂ�������B
���@�������Ă�킯�ł͂Ȃ���ŁA�܂��ƂɃS�����i�T�C�A���Ƃ͎��ۂɂ���Ă݂Ă݂ā`�B
�E�}�N�����͂�������[('��')�U
�����ԍ��F23012109
![]() 2�_
2�_
���ƁA�܂��������ݏ��Ȃ߂���Ȃ�ŁE�E�E�A
�u�@�v�Ƃ��́u�@��ˑ������v�͎g��Ȃ��ق������������B
����l�̊��ɂ���ẮA�����������邱�Ƃ����������B
�G�����Ȃ�����Ȃ����Ƃ�����������B
�����ԍ��F23012110
![]() 1�_
1�_
>���ł�DISK2�͂WTB�ɂȂ��Ă��邱�ƁB
1��߂̌����́A�d�����Ă��������������H
�܂��A�u�f�B�X�N1��v��8TB�ɂȂ��Ă邾��������H
�u�{�����[���v�͕ς���Ă��Ȃ�������H
�u�e�ʂ̊g��{�^���v�́A�łĂ��Ȃ�������H
����ł��[������B('��')
��ŁA�d�����Ă���A�����������ۂ�����ւ��Ă݂Ă��������ˁ[�B
�����ԍ��F23012128
![]() 2�_
2�_
��Excel����
��1��߂̌����́A�d�����Ă��������������H
�����ł��B
���܂��A�u�f�B�X�N1��v��8TB�ɂȂ��Ă邾��������H
�����ł��B
���u�{�����[���v�͕ς���Ă��Ȃ�������H
�����ł��B
���u�e�ʂ̊g��{�^���v�́A�łĂ��Ȃ�������H
�����ł��B
������ł��[������B('��')
�\�t�g����u�f�B�X�N�g���v�Ƃ����Ȃ��ł��A
���d�����Ă���A�����������ۂ�����ւ��Ă݂Ă��������ˁ[�B
�ł�����ł���ˁB
�d�����Ă������ւ���A���R�Ɂu�e�ʂ̊g��{�^���v���o�Ă����ł���ˁH
���ƁA�u�@��ˑ������v�̌��A���ӂ��܂��B
���肪�Ƃ��������܂��B
�����ԍ��F23012150
![]() 0�_
0�_
>�\�t�g����u�f�B�X�N�g���v�Ƃ����Ȃ��ł��A
���������̂͂����ˁA2��Ƃ������������Ă�������B
>�d�����Ă������ւ���A���R�Ɂu�e�ʂ̊g��{�^���v���o�Ă����ł���ˁH
����ւ��āA�č\�z���I����Ă�������ˁB(^_^)v
�����ԍ��F23012210
![]() 1�_
1�_
��Excel����
����Ă݂܂����B
�P�@�|�[�^�����O�C��
�Q�@�X�g���[�W�}�l�[�W���[�Ń{�����[���[�Ǘ�
�@�@�u�����f�B�X�N��傫���f�B�X�N�ƌ����D�D�D�v
�R�@NAS���V���b�g�_�E������HDD����
�S�@NAS�N��
�T�@���Ȃ�ƃ|�[�^�����N���������A�����ݒ���
�@�@���\���I�I
�U�@����Ă�NAS���V���b�g�_�E�����āAHDD�����ǂ��ċN�������ǂ���
�|���ĉ����o���Ȃ��Ȃ肻���ł��B
�����ԍ��F23012438�@�X�}�[�g�t�H���T�C�g����̏�������
![]() 1�_
1�_
���̌��60���̕ԐM������܂��B
NAS(�l�b�g���[�NHDD) > ASUSTOR > AS-608T
����g���Ă���AS-608T�̗e�ʂ������ς��ɋ߂Â��A���ł����鎖�����e�ʃA�b�v�����݂��̂ł���
3TB7�䁨6TB7��֕ύX���A�e�ʂ��{�ɂȂ�Ɗ��҂��Ă��܂������A�S�R���Ȃ��e�ʂŊg�����~�܂��Ă��܂��܂���
��̖�16.3TB��32TB�����҂��Ă����̂ł����A���̂�21.54TB�Ŏ~�܂��Ă��܂��A�ēx�e�ʊg�����悤�Ƃ��āA�u�e�ʂ̊g��v�{�^���������Ă���u�Ő���I�����Ă��܂��A�S���g������Ȃ���Ԃł�
�ǂȂ����������琳��ȗe�ʂɖ߂����@���������Ȃ��ł��傤��
![]() 0�_
0�_
������Ə���Ȃ����āA�悭���J���i�C��������ǁE�E�E
�͂��߂͂ǁ[�������{�����[���\�����������̂��A�ǂ������菇�ŁA�ǂ�����č�Ƃ��Ă������̂����A�u�ȗ����Ȃ��Łv�A�u�ڂ����v�����Ă��炤�ƁA�Ȃɂ������Ă��邱�Ƃ����邩������Ȃ������B('��')
�����ԍ��F22964351
![]() 1�_
1�_
�ȉ��̎菇�ŗe�ʊg�����s�����̂ł��傤��?
3. NAS �̗e�ʂ��g�傷��
3.1 �����̃n�[�h�f�B�X�N�����傫�ȃf�B�X�N�ɒu��������
�X�e�b�v 4
����ŁA�ŏ��̃f�B�X�N���������鏀���������܂����B [�X�e�[�^�X:]�t�B�[���h�ɏo��w���ɏ]���A�f�B�X�N��
���v���Z�X������ǂ��čs�����Ƃ��ł��܂��B �ŏ��̃f�B�X�N�̃h���C�u�g���C�����o���A�Â��f�B�X�N��V����
�傫�ȗe�ʂ̃f�B�X�N�ɒu�������܂��B
http://download.asustor.com/college/jpn/NAS_352_Online_RAID_Level_Migration_and_Capacity_Expansion.pdf
�w��̖�16.3TB��32TB�����҂��Ă����̂ł����A���̂�21.54TB�Ŏ~�܂��Ă��܂��A�x
RAID���x���́ARAID5�Ȃ̂ł��傤��?
�ȉ��̃y�[�W�Ōv�Z����ƁARAID5�iHOTSPARE���F0��j��3TB*7�䁁18TB(16.3TB)�A6TB**7�䁁36TB(32.7TB)
http://ferrets-forest.com/pc/hddcapa.htm
�����ԍ��F22964362
![]() 1�_
1�_
���ƁA�ЂƂ̒�ĂƂ��āA
�u�Ȃ�Ƃ��Ă��E�}�N�����Ȃ��`(:_;)�v
���Ă��ƂȂ�����ˁA�������̂��ƁA�T�N�b�Ə��������āA�o�b�N�A�b�v����߂����ف[�������͑�����������Ȃ������˂��B
���b�`�����A�o�b�N�A�b�v�͂���������ˁH
�����ԍ��F22964363
![]() 1�_
1�_
�X�~�}�Z���A�����R�炵�܂����B
�u�I�����C�� RAID ���x���ڍs�Ɨe�ʊg��v�̎菇6�ő}�������f�B�X�N��6TB�ŔF������Ă��܂���?
�X�e�b�v 6
�f�B�X�N�̌������I��������ANAS �Ƀh���C�u�g���C��߂��܂��B �f�B�X�N�͓��������J�n���܂��B �f�B�X�N��
���������I������ƁA�������ɕK�v�Ȏ��Ԃ̓n�[�h�f�B�X�N�̗e�ʂƃn�[�h�f�B�X�N�ɕۑ����ꂽ�f�[�^��
�ɂ���ĈقȂ�܂��B �]���āA�P��f�B�X�N�̓������ɂ͊����܂Ő����Ԃ�����܂��B[�X�e�[�^�X:]�t�B�[���h
�� 2 �Ԗڂ̃f�B�X�N�̌������J�n�ł���Ƃ����w�����\������܂��B �{�����[���̂��ׂẴf�B�X�N��������
���܂ŁA�ŏ��̃f�B�X�N�ɑ��čs�����菇�ɏ]���܂��B
�����ԍ��F22964383
![]() 1�_
1�_
 |
|---|
HDD�̏�Ԃł� |
�ŏ��ɏ��������͂��܂�ɍׂ��������߂��Ăׂ�ڂ��ɒ����Ȃ��Ă��܂��A�Z���܂Ƃ߂����肪�Z�߂��܂����B
���߂ďڍׂ��L�ڂ����Ē����܂��B�����ɂȂ��Ă��܂��܂��������e�͉������B
�T��LsLover����ɏ����Ē������A
http://download.asustor.com/college/jpn/NAS_352_Online_RAID_Level_Migration_and_Capacity_Expansion.pdf
�́A3.1�����̃n�[�h�f�B�X�N�����傫�ȃf�B�X�N�ɒu��������
�̎菇�ɏ]���Ă�낤�Ƃ����̂ł����A���̃}�j���A���ׂ����Ƃ��낪�F�X����Ă���A���������̂��d�Ȃ�A�r�����Ȃ�̂��₵�܂����B
1��ڂ̃f�B�X�N������������A���̃f�B�X�N����������悤�������b�Z�[�W�͂ǂ��ɂ��o�ė��܂���ł����B
�����č\�z���I�������A��������肾������ł��B
�ŁA2��ڂ̌���������O�ɍēx�X�e�b�v1�����蒼���܂����B
2��ڂ̍č\�z���I���ƁA���x�́u���̃f�B�X�N��e�ʂ̑傫�Ȃ��̂ƌ����`�v�Ƃ�������|�̃��b�Z�[�W���o�ė��܂����B
����ȍ~�͏����ɑ������̂ł����A7��ڂ��������č\�z���n�܂���1���Ԃقnjo�߂������A6��ڂ̃f�B�X�N�ɕs�ǃu���b�N��������A�ԃ����v���_�����ăA�N�Z�X�s�\�ɂȂ�܂����B
���̎��͂��Ȃ�̂��₵�܂������A���s����̌��ʁA6��ڂ�7��ڂ��Â��f�B�X�N�Ɍ������鎖�ōč\�z���ĊJ����A�f�[�^�͕ۑS����܂���(���Ȃ��Ƃ�����������)�B
���Ȃ݂ɂ����܂�1�䓖����15�`16���Ԃ������Ă���̂ŁA1��ڂ̌����Ɏ��|�����Ă���1�T�Ԉȏ�o�߂��Ă��܂��B
���̍č\�z���I�������A�ēx�X�e�b�v1����n�߁A6��ځA7��ڂ̃f�B�X�N�����ւ��y�эč\�z���I���ƁA�u�e�ʂ̊g��v�{�^�������ꂽ�̂ŁA�������A���ʂ�����̂悤�ȏ�Ԃł����B
��LsLover����
RAID5�ł��B
HDD��6TB�ŔF�����Ă��܂��B
�S���������[�J�[�A�����^�Ԃő������̂ł����A���̂�1�䂾��S.M.A.R.T��o�ė��Ȃ����̂�����܂����E�E�E
��Excel����
�o�b�N�A�b�v�͂���܂���B
���z�͖ܘ_�m���Ă��܂��B
���������̒��̐l�B�͖{���Ɏ������g���Ă���e�ʂ̔{�ȏ�̃o�b�N�A�b�v���m�ۂ��Ă����ł��傤���H
�R�����\�Z�Ɨ~�����e�ʂ𑊒k��5�N�O�ɏn�l�������ʁA
�u����NAS��1��\����HDD��d��on��Ԃŏ�����A�c��7���RAID5��g�݁A�T1�őS�Ă�HDD�̃f�B�X�N�`�F�b�N���s���v
��
�u�f���ɑ�e��HDD��2������t����v
��2������NAS�̗������l�����đO�҂�I��������NAS���w�����܂����B
���ۂ��̕��@��(���v�Ƃ͌�����Ȃ��Ă�)���Ȃ��v�ł����B
�������A�ߋ��ɂ�1�T�Ԃ��炢�̊Ԃ�2�䗧�đ�����HDD���̏Ⴕ����������̂ŁAHDD�̕�[���x�������烄�o�������̂����m��܂��A�����܂Ō����o�����狰�炭�����e�ʂ�HDD��p�ӂ��ă~���[�����O���Ă����l�ɔ������Ȃ����̂Ƃ������̂͂���Ǝv���Ă��܂��B
����ł͗e�ʃA�b�v�ׂ̈ɓ���ւ���3TB��HDD��8�䂠��܂��̂ŁA�ꎞ�I�ɂ����ɏ���NAS�̓��e���o�b�N�A�b�v���A���������Ė߂���������ɓ���Ă���܂����A�������̑���Ŋ��҂����e�ʂ��m�ۂ����Ȃ炻�ꂪ��Ԃ��肪�����̂ŁA�ǂ��ɂ��Ȃ�Ȃ����̂��Ǝ��₳���Ē�������Ԃł��B
���ݖ���NAS�͏������ɔ����ăo�b�N�A�b�v���n�߂��Ƃ���A�r���Ŏ~�܂��Ă��܂��E���Ƃ��X���Ƃ�����Ȃ��Ȃ��Ă��܂����̂ōċN�������Ƃ���A1���Ԍo���Ă��ċN�������A������ƋC�ɂȂ鎖���������̂�1��ڂ�HDD����x�����ėl�q���m�F���Ė߂��A�A�N�Z�X���~�܂����̂�2�x�ڂ̍ċN���������Ƃ���A����1��ڂ�HDD�ɑ��čč\�z���n�߂Ă��܂��A����20���ԑ҂��˂ΏI���Ȃ��悤�ł��B
�g�z�z�E�E�E
����͂���ς�S���o�b�N�A�b�v���ď��������邵���Ȃ��ł����ˁB
�����ԍ��F22965696
![]() 0�_
0�_
>���ۂ��̕��@��(���v�Ƃ͌�����Ȃ��Ă�)���Ȃ��v�ł����B
����ς������E�E�E�Ƃ��Ă��S�z�����B
�u�f�[�^��NAS�ŏW���Ǘ����ĕ֗��Ɏg���邱�Ƃ����D��A�g������Ƃł�����B( �M�[´)�m�v
���Ċo��͂��Ă�����Ă��Ƃ�����ˁB
��ł���A���Ƃ͑��l�ɂ͂ȁ[��������Ȃ������B
��ł��ANAS�{�̂��I�V���J�ɂȂ��āA�n�[�h�f�B�X�N����Ƃ���@����Ă��Ƃ́E�E�E
�u����Ȃ��Ƃ͂��肦�Ȃ�������[�I�v
�E�E�E�E���������A�ӂ[�ɂ��肦�邱�ƂȂ�B
���܂ł́A�^�}�^�}�^���悩�����������Ă��Ƃ����B
>����1��ڂ�HDD�ɑ��čč\�z���n�߂Ă��܂��A����20���ԑ҂��˂ΏI���Ȃ��悤�ł��B
>�g�z�z�E�E�E
�����āA����Ȃ��Ƃ���葱���Ă��邤���ɁA�u���E�b�J���E�E�E�v�Ȃ�Ă��Ƃ��N�����Ă��܂�����E�E�E((((�G߄D�))))��������
�����ԍ��F22965730
![]() 1�_
1�_
�S�Ă��o�b�N�A�b�v����R�X�g�͂������Ȃ��E�E�E�B
�킩��܂��A���`�킩��܂��Ƃ��B('��')�U
�o�b�N�A�b�v�́u���ʁv�������˂��B
�E�[�b�^�C�ɖ����������Ȃ����ǁA�X�V����邱�Ƃ��Ȃ����́B�ʐ^�Ƃ�����Ƃ��B
�u���[���C�ȂǂɃo�b�N�A�b�v�B
�E�[�b�^�C�ɖ��������P�ɂ͂����Ȃ��āA��ɎQ�ƁA�X�V�������́B
USB�n�[�h�f�B�X�N�ȂǂɎ����o�b�N�A�b�v�B
�E�g�������炢������Ă��́E�E�E�o�b�N�A�b�v���Ȃ��B(;^_^A
�[���ƂŁA�o�b�N�A�b�v�_�́A�܂��ʂ̋@��ɂ��Ă��ƂŁA���́A�o�b�N�A�b�v��������ԂŁA�e�ʊg�����ǂ����邩���Ă��ƂɁA�O����߂��܂���[�B(*'��')
�����ԍ��F22965764
![]() 1�_
1�_
���ƁA�݂Ȃ���悭���Ⴂ����Ă��邱�ƂȂ̂ł����ANAS��RAID�Ƃ����̂́A�o�b�N�A�b�v�̂��߂̋Z�p�ł͂Ȃ��A�^�p���Ƃ߂Ȃ����߂̋Z�p�ł������܂��B
�^�p���Ƃ߂Ȃ��Z�p�ł����āA�������ăo�b�N�A�b�v�̂��߂ł͂Ȃ��Ƃ������Ƃł����B
�E�f�[�^��NAS�ɂ������݂��Ȃ��ꍇ�ɂ́A���Ƃ�RAID�ł����Ă�����̓o�b�N�A�b�v�ł͂���܂���B
�EPC�Ƀf�[�^�����݂��A���̃R�s�[�Ƃ������Ƃł���ANAS�̓o�b�N�A�b�v�ƂȂ肦�܂��B
�����ԍ��F22965785
![]() 1�_
1�_
�w���̍č\�z���I�������A�ēx�X�e�b�v1����n�߁A6��ځA7��ڂ̃f�B�X�N�����ւ��y�эč\�z���I���ƁA�u�e�ʂ̊g��v�{�^�������ꂽ�̂ŁA�������A���ʂ�����̂悤�ȏ�Ԃł����B�x
���̎��ɐV����6TB��HDD�̃p�[�e�B�V�������폜�����ɁA����ւ����s�������Ƃ��C�ɂȂ�܂��B
�V�����eHDD�̃p�[�e�B�V�����T�C�Y��Array Size�AUsed Dev Size�Ȃǂׂ�ƁA�����������߂邩������܂���B
MDADM�ɂ��RAID5�̗̈�̊g��E�k��
http://neet.waterblue.net/2011/11/03/mdadm%E3%81%AB%E3%82%88%E3%82%8Braid5%E3%81%AE%E9%A0%98%E5%9F%9F%E7%B8%AE%E5%B0%8F/
�����ԍ��F22966678
![]()
![]() 1�_
1�_
�{�����[�����̂́A���͂������������A�ǁ[��[�Ӂ[�ɔF������Ă���������H
�摜�����肢��������B
�����ԍ��F22966689
![]() 1�_
1�_
 |
 |
|---|---|
�X���b�g1�`5 |
�X���b�g6�`7 |
��LsLover����
��Excel����
�eHDD��6TB�ŔF������Ă��܂��B
�ʏ�\������Ȃ��u�e�ʂ��g��v�{�^�����\������Ă��܂��̂ŁA�ނ������������ɋC�t���Ă͂���l�q�Ȃ�ł����A��̉����C�ɓ���Ȃ��̂��E�E�E
�������ȓ_�Ƃ����A�C�ɂȂ�̂�S.M.A.R.T�X�L���������Ă����S.M.A.R.T��o�ė��Ȃ��f�B�X�N4�ł����ˁB
���������6TB�ŔF������Ă܂����A�e�ʂ̓_�ł͖�肠��悤�Ɍ����Ȃ���ł����B
�����ԍ��F22967439
![]() 0�_
0�_
�n�[�h�f�B�X�N�́A�܂�����̐V�i�������H
�ꎞ�I�ɂł��A�Ȃɂ��ʂ̂Ƃ���ŁA�Ȃ������̂��Ă��Ƃ͂Ȃ��������H
�����ԍ��F22967555
![]() 1�_
1�_
>���������6TB�ŔF������Ă܂����A�e�ʂ̓_�ł͖�肠��悤�Ɍ����Ȃ���ł����B
���Ƃ��Ă��A�u�ق��ƈႤ�v��ł���A�܂��́A�u�ق��Ƃ���Ȃ��v�ɂ��邱�Ƃ��͂��߂��Ȃ��ċC�͂�������ˁ[�B
�����ԍ��F22967558
![]() 1�_
1�_
��Excel����
HDD�͒��Âł��B
����܂�C�͐i�܂Ȃ��ł������������ʂ�Ȃ̂ŃX���b�g8�ƃX���b�g4�����ւ��Ă݂悤�Ǝv���܂��B
�܂�26���Ԃ��炢�č\�z�ɂ�����̂��Ȃ��E�E�E
����ŗe�ʂ̖�肪�������Ă��܂����ꍇ�A��Q���o�����̔����Ƃ��Ă���HDD���A�e�ɂł��Ȃ��Ȃ�̂�����Ȃ��B
�����������Âň����ς܂����Ӗ��������Ȃ����Ⴄ�B
�����ԍ��F22967754
![]() 0�_
0�_
>HDD�͒��Âł��B
���`����͂����˂��A��������PC�Ɏ��t���āA�u���S�������v���Ȃ��ƃ_�����Ǝv��������`�B
�����O�ɁA�p�[�e�B�V�����Ƃ��AMBR�Ƃ����܂߂āA�u�z���g�[�ɋ���ہv�ȏ�Ԃł��邱�Ƃ́A������Ɗm�F���Ă���g���Ă���������H
�u���`��Ԓ��Áv������������ˁA�uPC���g���āA���`��Ԋ��S�������v���Ă���g��Ȃ��ƁA�Ȃɂ��N���邩���J���i�C������[�B('��')
�����ԍ��F22967773
![]() 1�_
1�_
��Excel����
�}�W�ł���������
�����S.M.A.R.T��o�ė��Ȃ��f�B�X�N���g����悤�ɂȂ�Ƃ��肪�������ǁE�E�E
���ԂɎ����Ă݂܂��B
�č\�z��1�X���b�g������26���Ԃ��炢������̂Ō��ʕ͗��T�ȍ~�ɂȂ�܂�orz
�����ԍ��F22967865
![]() 0�_
0�_
���Â͂ˁA�ǁ[��[���Ŏg���Ă��������J���i�C��ŁA�g���O�́u���S�������͕K�{�I�v���čl�����ق����A�g���u������ɂ͂Ȃ�����ˁB
������ǂ��E�E�E�A
>�����S.M.A.R.T��o�ė��Ȃ��f�B�X�N���g����悤�ɂȂ�Ƃ��肪�������ǁE�E�E
����Ɋւ��ẮA�]�ݔ����Ƃ͎v�����ǂ˂��E�E�E�B
�Ȃ�����Ă邤���ɁA�ȂN���Ă��܂�Ȃ����ƁA�q���q�����Ă��������[�B(;^_^A
�o�b�N�A�b�v�Ɏg����A�O�̂��̂����������A�u���̈�Ԃɂ�邱�Ƃ̓o�b�N�A�b�v�v�ł͂Ȃ��̂��Ȃ����čl�����������ǂ˂��E�E�E�B
�u�����ɗ������v�ł������܂���[�B
�����ԍ��F22967954
![]() 1�_
1�_
��ŁA���܂́A���Â̂܂܂�����ł��ŁA���낢�남�������킯�ŁA�o�b�N�A�b�v������Ă���A�T�N�b��NAS�Ŋ��S���������Ă��܂��A���[�������̂ق���������łȂ��̂�����B
>�č\�z��1�X���b�g������26���Ԃ��炢������̂Ō��ʕ͗��T�ȍ~�ɂȂ�܂�orz
�[���A���^�N�V��������A����Ȃɑ҂��Ă����Ȃ������B
�����ԍ��F22967964
![]()
![]() 1�_
1�_
��Excel����
�m���ɑS������Ă�ԂɂȂN���܂��˃R���B
�����X���b�g����ւ��Ă��܂����̂Ŗ����܂ł͌���邵���Ȃ��ł����A�I�������o�b�N�A�b�v����ď���������������ԓI�ɂ��}�V�ł����A�������̕����ōs���܂��B
�ǂ����ɂ��Ă��ŏI�͌�ł��܂��ˁB
�����ԍ��F22968004
![]() 0�_
0�_
��荇�������C�t��������ł����AS.M.A.R.T��E���Ȃ�������̃f�B�X�N�A�t�H�[�}�b�g������S.M.A.R.T���o��悤�ɂȂ�܂����B
�R���̃��r���h�I��������_�ŗe�ʊg���ł�����ǂ��Ȃ��B
�����ԍ��F22968131
![]() 0�_
0�_
���̌��6���̕ԐM������܂��B
NAS(�l�b�g���[�NHDD) > ASUSTOR > AS3102T
 |
|---|
���O��HDD�A������HDD |
�O���@��Ƃ��Đڑ����Ă���HDD�̗e�ʂ����ۂ������Ȃ��\������܂��B
4TB�܂Ŏg�p�Ƃ���Ă���HDD�P�[�X��8TB��HDD��ڑ����Ă��邱�Ƃ������ł��傤���H
https://kakaku.com/item/K0000337269/
���̑�������������@�����킩��Βm�肽���ł��B
����HDD�P�[�X��win10�}�V���ɐڑ����Ă����e�ʁA�e�ʂɕω��͂Ȃ��ł��B
�g�p��
AS3102T���� WD RED 4TB×2 ��RAID0
�O���@�� WD RED 8TB�@(1�x�C�͋B�ʔF�����郂�[�h���g�p)
����HDD�̓��e���܂���ƊO���@��Ƀo�b�N�A�b�v����^�p�����Ă��܂��B
����HDD�̎g�p�e�ʂƊO���@��̋e�ʂ���l����ƁA8TBHDD��4TB�������g���Ă��Ȃ��̂�������܂���B
![]() 0�_
0�_
���e�ʂ݂��7TB�ȏ�̐������o�Ă���^�����Ɍ����܂��B���������̂͂ǂ̕����ł����H
�����ԍ��F22640462�@�X�}�[�g�t�H���T�C�g����̏�������
![]() 0�_
0�_
>����
�p�b�P�[�W�ɋL�ڂ��ꂽ�e�ʂƃp�\�R���Ȃǂ��F������e�ʂ̒P�ʊ��Z���@���قȂ邽�߂ł��B
�p�\�R�����́A1TB��1024GB�A1GB��1024MB�Ƃ����������ŁA1024���ɗe�ʂ̒P�ʂ�1�オ���Ă��܂��B
�ł����A�p�b�P�[�W�ɋL�ڂ��ꂽ�e�ʂ́A1TB��1000GB�A1GB��1000MB�ƁA1000���ɗe�ʂ̒P�ʂ��オ��܂��B
���̈Ⴂ�ɂ���āA�e�ʂ̒P�ʂ�TB(�e���o�C�g)�ɂȂ��Ă��鐻�i�̏ꍇ�A�p�\�R���ɂ͖�10���قǏ��Ȃ��e�ʂŔF������܂��B
>�������@
����܂���B
�����_�̔F���Ő���ł��B
�����ԍ��F22641190
![]() 0�_
0�_
����Ȃ��̂����B
�Ȃ�ɂ��S�z����Ȃ������B
�܂��A����Ɋւ��Ă͂����ˁA�����Ȏ��������ǁA
���������A8TByte��8000GByte�ł͂Ȃ����āA�ׂ����v�Z������Ɓu7.28TByte�v���炢�ɂȂ�B
�����ԍ��F22641546
![]() 0�_
0�_
���Ȃ݂ɁA2TByte�h���C�u���Ƃ����ˁA�u1.8TByte�v���炢�ɂȂ������B
������A�u1.8TB�v�Ƃ����ĕ\������̂��߂�ǂ���ŁA�U�b�N���Ɓu2TB�v���āA�͂�����Ă���Ă��Ƃ����B
�����ԍ��F22641650
![]() 0�_
0�_
�L�ڗe�ʂ�1�L���o�C�g��1000�o�C�g�Ōv�Z���܂����APC�̎��ۂ̗e�ʂ́A1�L���o�C�g��2��10��=1024�Ōv�Z���܂��B
1���K�o�C�g�͂����1�L���o�C�g��1024�{�A�ݐς��čs���ƋL�ڗe��8TB�ł��ƁA���e��7.275TB�ɂȂ�܂��B
�����ԍ��F22647670�@�X�}�[�g�t�H���T�C�g����̏�������
![]() 0�_
0�_
��amg288857����
��Excel����
��ktrc-1����
��kockys����
�������݂��肪�Ƃ��������܂��B
���������肸�A�Ӑ}���Ă������e������ł��Ă��܂���ł����B
����HDD��3.55TB�Ɠ����f�[�^���O��HDD�ɏ�������ł���A�O��HDD�ɂ͂��̑��̃f�[�^�͋L�^���Ă��܂���B
���̏ꍇ�A����HDD�ƊO��HDD�̎g�p�ςݗe�ʁA�e�ʂ͓������炢�ɂȂ�Ǝv���܂��B
�O��HDD�̑��e�ʂ͐������F������Ă���悤�Ɍ����܂��B
�O��HDD�ɋL�^���Ă���f�[�^���t�@�C���G�N�X�v���[���[��Ŋm�F�����3.58TB�ł����A�f�B�X�N�̏��ł�7.01TB���g�p�ς݂Ƃ���Ă��܂��Ƃ������ł��B
3.5TB�����g�p���Ă��Ȃ��̂Ɏg�p�ς݂Ƃ��Ĉ����Ă���悤�ł��B
�����ԍ��F22649118
![]() 0�_
0�_
>�O��HDD�ɋL�^���Ă���f�[�^���t�@�C���G�N�X�v���[���[��Ŋm�F�����3.58TB�ł����A�f�B�X�N�̏��ł�7.01TB���g�p�ς݂Ƃ���Ă��܂��Ƃ������ł��B
�Ȃɂ��̊��Ⴂ������悤�Ɏv���������B
�o�b�N�A�b�v�͎蓮�R�s�[�H
�o�b�N�A�b�v�A�v���A�����A�v���Ȃg���ĂȂ��������H
�����āA���̒��ŁA����Ǘ��A�o�[�W�����Ǘ��Ȃ��L���ɂȂ��Ă��Ȃ��������H
�����R�s�[���ɗL���ɂȂ��Ă���ƁA���悻2�{�ɂȂ����肷�������B
�����ԍ��F22649168
![]()
![]() 0�_
0�_
 |
|---|
�o�b�N�A�b�v�ƕ��� |
��Excel����
�w�������炠��u�o�b�N�A�b�v�ƕ����v�ɂāA����I�Ɏ����Ńo�b�N�A�b�v�����s�����悤�ɐݒ肵�Ă��܂��B
����Ǘ����̐ݒ�͌�������܂���B
�����ԍ��F22649326
![]() 0�_
0�_
 |
|---|
���O��HDD�A������HDD |
�O��HDD����x�t�H�[�}�b�g���Ă݂��Ƃ���A���e�ʁA�e�ʋ���7.28TB�ɂȂ�܂����B
���̏�Ԃ���o�b�N�A�b�v�W���u�����s�����̂��摜�̏�Ԃł��B
����HDD�ɑ��ĊO��HDD�̕����g�p�ς݂��傫���Ȃ��Ă��܂����A�O��HDD�̋e�ʂ��Ԉ���Ă��Ȃ����ł��B
�o�b�N�A�b�v���@�ɖ�肪�Ȃ������ēx�����Ă݂悤�Ǝv���܂��B
�����ԍ��F22650852
![]() 0�_
0�_
�o�b�N�A�b�v�̉��d�˂�ɂ�ĊO��HDD�̐�L�����オ�邱�Ƃ��m�F�ł��܂����B
���̊ԓ���HDD�̐�L���͏オ���Ă��܂���B
�����o�b�N�A�b�v��ݒ肵�Ă��܂����A���ۂ̓���͍����o�b�N�A�b�v�ɂȂ��Ă���̂�������܂���B
�����ԍ��F22658677
![]() 0�_
0�_

�N�`�R�~�f������
�œK�Ȑ��i�I�т��T�|�[�g�I
[NAS(�l�b�g���[�NHDD)]
�V���s�b�N�A�b�v���X�g
-
�y�~�������̃��X�g�z����PC
-
�y�~�������̃��X�g�z�T�uPC�i�O���{�A�d�����p�j
-
�y���̑��z27�C���`���j�^�X�s�[�J�[����
-
�yMy�R���N�V�����z20210814�쐬
-
�yMy�R���N�V�����z���C��PC 2024 [i7-14700K DDR5 64GB RTX4090]
���i.com�}�K�W��
���ڃg�s�b�N�X
- �m�[�g�p�\�R����������9�I�I �p�r�ʂ̃R�X�p�ŋ����f���y2025�N11���z

�m�[�g�p�\�R��
- �p�i�\�j�b�N �u���[���C���R�[�_�[�̂�������5�I�I ���S�Ҍ����̑I�ѕ�������y2025�N12���z

�u���[���C�EDVD���R�[�_�[
- �r���[�J�[�h �X�^���_�[�h��JRE CARD�̈Ⴂ�͉��H ��ׂĂ킩�����u���܂��g�����v

�N���W�b�g�J�[�h
�i�p�\�R���j
NAS(�l�b�g���[�NHDD)
�i�ŋ�3�N�ȓ��̔����E�o�^�j




